In the Later Roman Empire (4th-6th centuries AD), the Roman emperors frequently referred to themselves (and were referred to) with rhetorical appellations such as Nostra Clementia (“Our Clemency”) and Nostra Tranquillitas (“Our Tranquility”). These titles are ubiquitous in the Late Roman Law codes, and in a number of letters, panegyrics, and other writings addressed to the emperors. I am interested in conducting both “distant” and “close” readings of the usage of these titles, and so am using R for the former.
For this week’s blog post, I have taken the raw text of the Theodosian Code, a fifth century legal compilation of imperial laws, and searched for occurrences of the terms (in all of their inflections) Nostra Clementia, Nostra Mansuetudo, Nostra Tranquillitas, and Nostra Serenitas. The Theodosian Code is divided into 16 “Books”, and so I chunked the text accordingly:
| Book | Clementia | Mansuetudo | Tranquillitas | Serenitas |
| 1 | 3 | 3 | 1 | 3 |
| 2 | 3 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 1 |
| 5 | 4 | 0 | 1 | 2 |
| 6 | 6 | 3 | 2 | 7 |
| 7 | 7 | 1 | 0 | 2 |
| 8 | 9 | 4 | 1 | 6 |
| 9 | 7 | 1 | 0 | 8 |
| 10 | 3 | 5 | 0 | 1 |
| 11 | 8 | 7 | 1 | 8 |
| 12 | 10 | 6 | 0 | 1 |
| 13 | 2 | 2 | 0 | 1 |
| 14 | 4 | 1 | 0 | 2 |
| 15 | 4 | 5 | 0 | 7 |
| 16 | 11 | 3 | 3 | 4 |
The Theodosian Code contains laws dating from the reign of Constantine (306-337) through the early fifth century. The mass of imperial constitutions from this period was pruned and excerpted by the Code’s compilers, and organized into 16 Books according to subject matter. In some instances, the same law was split up, and its various pieces were placed in different parts of the Code. Therefore, there is not much utility in attempting to chart the changes in word frequency over the Code’s different sections. That being said, some (cautious) conclusions can be made about why the words are more frequent in certain Books of the Code rather than in others. For example, Nostra Clementia sees a spike in Book 8 because it deals with financial privileges and penalties – matters in which the emperor’s clemency was often invoked.
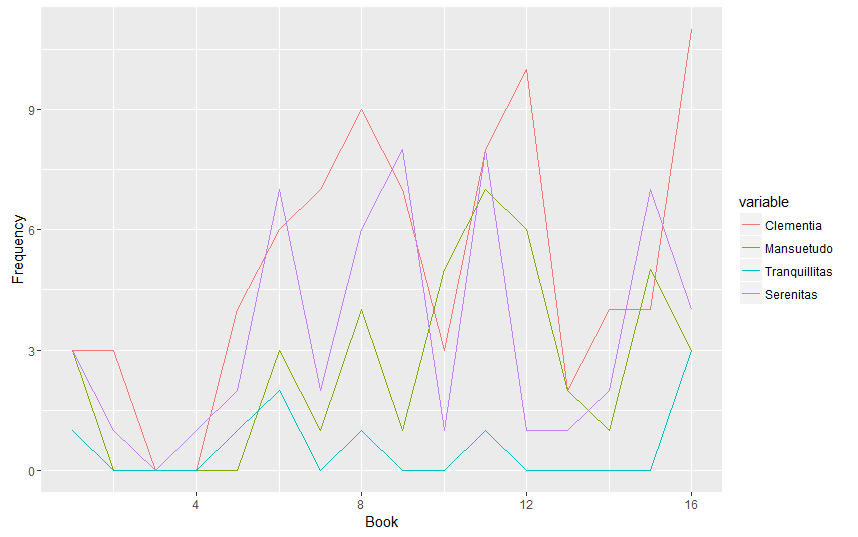
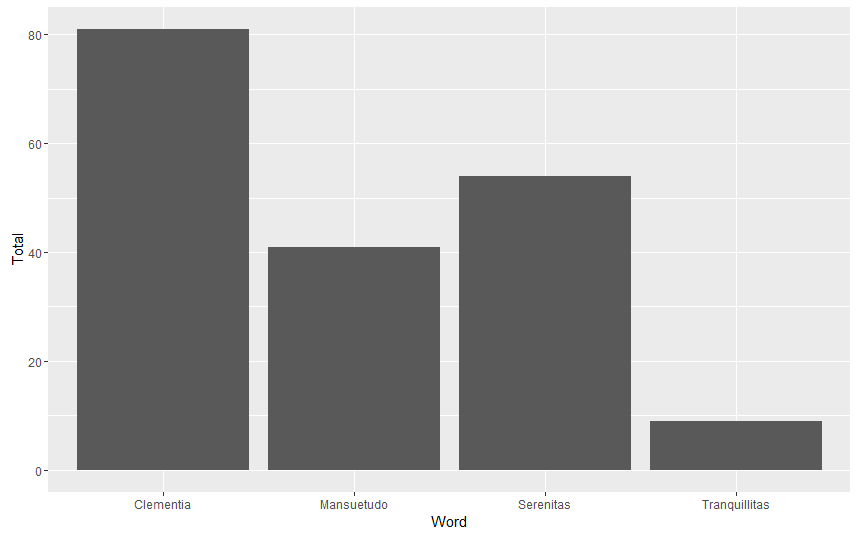
More immediately pertinent may be the sheer total number occurrences of each title within the Theodosian Code. Of the terms searched, Nostra Clementia is clearly the most common; this is understandable, for the emperor’s clemency was often invoked in his capacity as supreme legislator and judge.
I intend to continue to run searches for other imperial titles, both within the Theodosian Code, and in other texts. Once I have perfected my coding, it will be easy to replicate. The one major issue with which I am still faced, however, is the fact that word order matters little in Latin, and while I have found all of the instances of Nostra Clementia and Clementia Nostra, there are instances within the Code where other words are interposed between Nostra and Clementia. For example:

The phrase nostra scilicet super eorum nominibus edocenda clementia, “Our Clemency certainly ought to be informed of their names”, interposes the rest of the clause between nostra and clementia. I still need to figure out how to get R to find these instances and include them in my counts.
Code
CTh.scan <- scan(“~/Education/Emory/Coursework/Digital Humanities Methods/Project/Theodosian Code Raw Text.txt”,
what=”character”, sep=”\n”)
CTh.df <- data.frame(CTh.scan, stringsAsFactors=FALSE)
CTh.df <- str_replace_all(string = CTh.df$CTh.scan, pattern = “[:punct:]”, replacement = “”)
CTh.df <- data.frame(CTh.df, stringsAsFactors = FALSE)
CTh.lines <- tolower(CTh.df[,1])
book.headings <- grep(“book”, CTh.lines)
start.lines <- book.headings + 1
end.lines <- book.headings[2:length(book.headings)] – 1
end.lines <- c(end.lines, length(CTh.lines))
CTh.df <- data.frame(“start” = start.lines, “end”=end.lines, “text”=NA)
i <- 1
for (i in 1:length(CTh.df$end))
{CTh.df$text[i] <- paste(CTh.lines[CTh.df$start[i]:CTh.df$end[i]], collapse = ” “)}
CTh.df$Book <- seq.int(nrow(CTh.df))
CTh.df$Clementia <- str_count(string = CTh.df$text, pattern =
“nostra clementia|clementia nostra|nostrae clementiae|clementiae nostrae|nostram clementiam|clementiam nostram”)
CTh.df$Mansuetudo <- str_count(string = CTh.df$text, pattern =
“nostra mansuetudo|mansuetudo nostra|nostae mansuetudinis|mansuetudinis nostrae|
nostrae mansuetudini|mansuetudini nostrae|nostram mansuetudinem|mansuetudinem nostram|
nostra mansuetudine|mansuetudine nostra”)
CTh.df$Tranquillitas <- str_count(string = CTh.df$text, pattern =
“nostra tranquillitas|tranquillitas nostra|nostrae tranquillitatis|tranquillitatis nostrae|
nostrae tranquillitati|tranquillitati nostrae|nostram tranquillitatem|tranquillitatem nostram|
nostra tranquillitate|tranquillitate nostra”)
CTh.df$Serenitas <- str_count(string = CTh.df$text, pattern =
“nostra serenitas|serenitas nostra|nostrae serenitatis|serenitatis nostrae|nostrae serenitati|serenitati nostrae|
nostram serenitatem|serenitatem nostram|nostra serenitate|serenitate nostra”)
frequency.long <- melt(CTh.df, id = “Book”, measure = c(“Clementia”, “Mansuetudo”, “Tranquillitas”, “Serenitas”))
ggplot(frequency.long, aes(Book, value, colour = variable)) + geom_line() + ylab(“Frequency”) #Create Frequency Graph
clementia.sum <- sum(CTh.df$Clementia)
mansuetudo.sum <- sum(CTh.df$Mansuetudo)
tranquillitas.sum <- sum(CTh.df$Tranquillitas)
serenitas.sum <- sum(CTh.df$Serenitas)
Total <- c(clementia.sum, mansuetudo.sum, tranquillitas.sum, serenitas.sum)
Word <- c(“Clementia”, “Mansuetudo”, “Tranquillitas”, “Serenitas”)
word.sum.df <- cbind.data.frame(Word, Total)
ggplot(data=word.sum.df, aes(x=Word, y=Total)) + geom_bar(stat = “identity”) #Word Total Graph