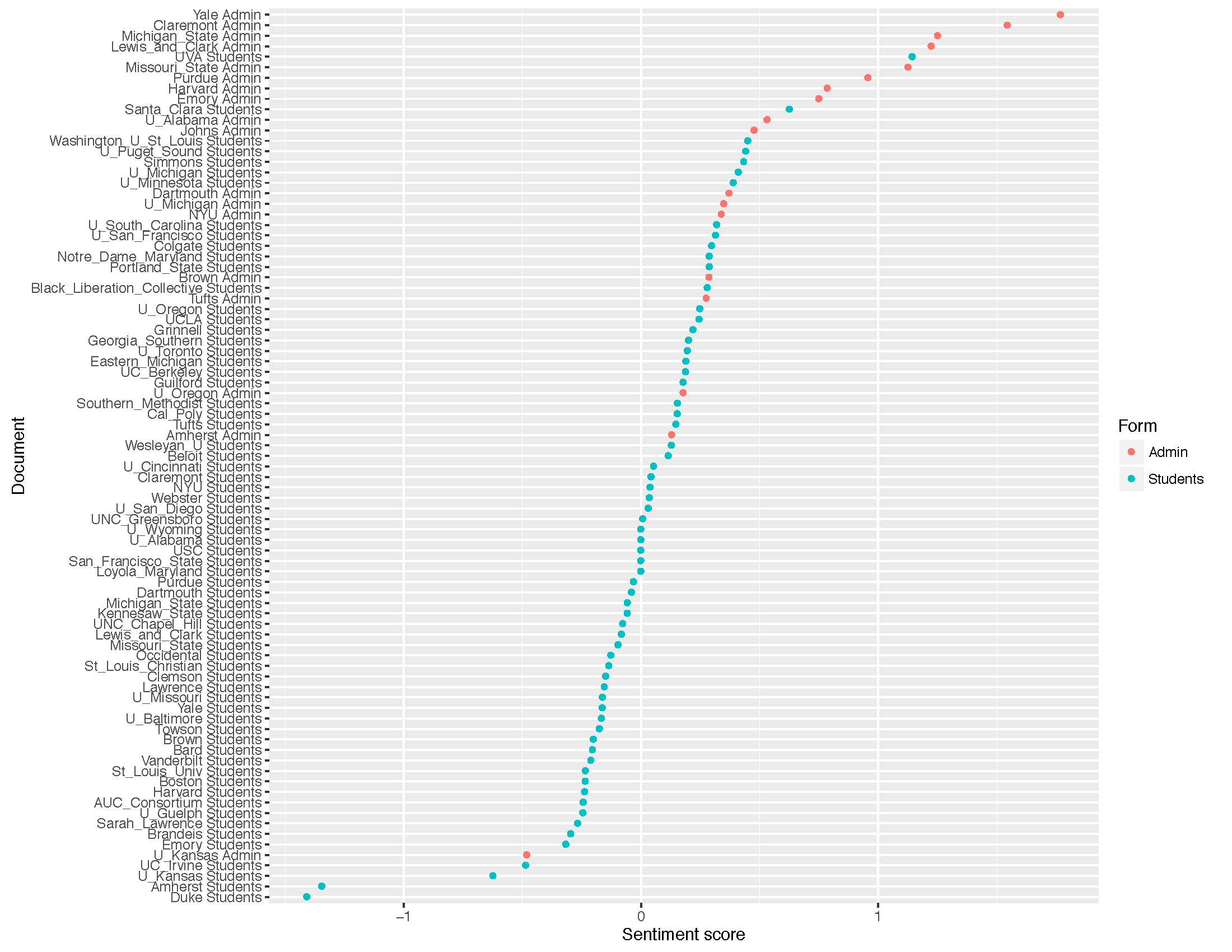
This is the first of a series of blog post applying text mining and other DH techniques to the evolving student protest movement demanding racial equality. What can DH techniques tell use about student demands and administration responses? Are faculty and students talking to each other or at each other? This project is a collaborative effort between Mark Ravina, a professor of history at Emory University, and TJ Greer, a soon-to-be Emory College graduate and history major.
The project emerged organically and fortuitously. In Spring 2015, TJ took Mark’s junior/senior colloquium on text mining, and then proposed a senior project focusing on the 2016 presidential primaries. Mark agreed, but after learning that TJ was active in the student protest movement, suggested a text mining project focusing on student protest petitions instead. TJ eagerly agreed, but suggested adding administration responses. TJ and Mark then scraped the data: the student demands are from www.thedemands.org/ but TJ supplemented these with administration responses. The current data set is 90 documents: 67 student demands and 23 administration responses
This collaboration has been exciting and productive, but has also raised multiple questions. As the protest movement continues to unfold, how can DH tools inform the movement, and how the protests can inform DH? Reflecting on our own subject positions, how should a fifty-something white professor ally and an African-American student activist work together, combining advocacy and analysis? Our goal, in these posts, is to toggle between these political and methodological concerns, including technical questions of text mining.
This first blog reflects our first preliminary results, but even at this early stage we feel comfortable with two declarations: one empirical and one political. The empirical observation is that university administrations are largely talking past students, employing a radically different vocabulary than that of student demands. Our political observation is that universities need to address student demands seriously and directly, even if that means admitting that some problems are deeply structural and that solutions will require decades rather than months or years.
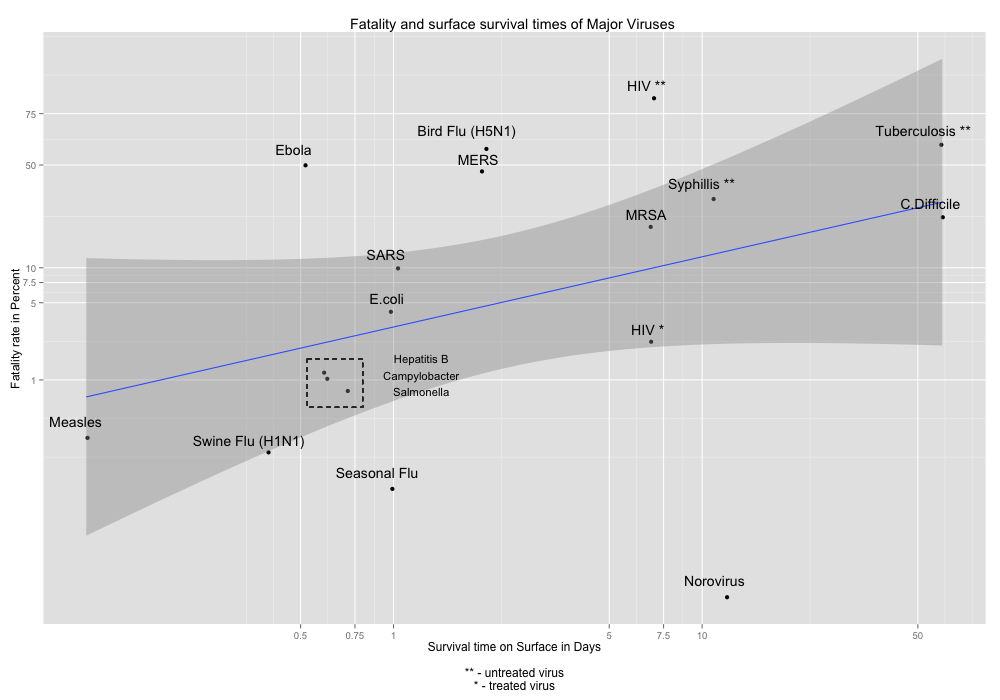
One basic measure of the disconnect between students demands and administration responses is lack of overlap between the most common words for each type of document. (Used the stopword list from the R package lsa and also removed proper nouns, such as school and building names). Comparing the 30 most frequent words in student and administration documents (using a standard stopword list), only 13 words appear in both lists. Eight of those 13 words lack a strong political valence: “students,” “university,” “student,” “faculty,” “campus,” “staff,” “college,” and “president.” Only five truly address the nature of student demands: “diversity,” “support,” “inclusion,” “multicultural,” “community.” Notably, even the usage of these five shared terms varies sharply. “Inclusion” is the eighth most common term in administration documents, but ranks 26th in student demands.
| Rank |
Students |
Administration |
Common (student rank / administration rank) |
| 1 |
students |
students |
students (1/1) |
| 2 |
demand |
university |
university (3/2) |
| 3 |
university |
community |
student (5/9) |
| 4 |
black |
diversity |
faculty (6/6) |
| 5 |
student |
campus |
diversity (7/4) |
| 6 |
faculty |
faculty |
campus (8/5) |
| 7 |
diversity |
staff |
staff (10/7) |
| 8 |
campus |
inclusion |
community (13/3) |
| 9 |
color |
student |
college (15/16) |
| 10 |
staff |
issues |
president (17/11) |
| 11 |
increase |
president |
support (18/12) |
| 12 |
center |
support |
inclusion (26/8) |
| 13 |
community |
programs |
multicultural (27/26) |
| 14 |
studies |
respect |
|
| 15 |
college |
plan |
|
| 16 |
demands |
college |
|
| 17 |
president |
commitment |
|
| 18 |
support |
inclusive |
|
| 19 |
cultural |
free |
|
| 20 |
academic |
diverse |
|
| 21 |
office |
shared |
|
| 22 |
training |
time |
|
| 23 |
program |
forward |
|
| 24 |
american |
ideas |
|
| 25 |
administration |
speech |
|
| 26 |
inclusion |
multicultural |
|
| 27 |
multicultural |
race |
|
| 28 |
people |
action |
|
| 29 |
funding |
freedom |
|
| 30 |
department |
values |
|
The disconnect between students demands and administration responses is revealed starkly in the usage of a few semantically rich terms, such as “color”, “demand”, “increase,” “respect”, “inclusion”, “community.” The first three are used frequently by students but relatively rarely by administration. The latter three are used frequently by administrations but relatively rarely by students.
We decide to explore this disconnect further by developing interactive scatter plot, to turn the differences in word frequency into physical distance. The “dialogue” that follows is an edited version of a series of exchanges, exploring 2D and 3D scatter plots. It is NOT a direct transcript, but reflects the essence of our in-office and email exchanges.
Mark: On the 2D scatter, I’m struck by the contrast between “increase” (x) versus “respect” (y). The student demands run up along the x-axis, with few uses of “respect” relative to “increase.” The administration responses run at a 90 degree angle along the y-axis, focusing on “respect” rather than “increase.” Huge areas of the plot are empty, because few texts use both the terms “respect” and “increase.” A close reading of the texts reveals that, indeed, students demands calls for “increases” in funding and administration responses call for mutual “respect.” The paucity of points in the center of the graph reflects the paucity of common ground. But what’s remarkable is how “respect” seems to have become a term of the establishment. Demands for “respect” were once a part of student activism. Not anymore.
TJ: There’s something roughly parallel in the 3D scatters for “inclusion,” “community,” and “respect.” The administrative responses (ARs) are disbursed throughout the 3D space, while most of the student demands (SDs) remain in a cluster near the 0,0,0 origin. The terms “inclusion” and “community” are much more common SDs than the term “respect.” However, the ARs as a whole use all three of the terms at a higher rate than the SDs. There’s an intriguing outlier, The University of Oregon AR. It does not include “inclusion,” “community” or “respect” and remains tucked away in the corner of the 3D space, at the 0,0,0 point, clustered with the students and away from the other ARs data points. (You may need to rotate to graph to see it). Interestingly, the University of Oregon AR opens with the following: “We have an opportunity to move forward as a campus that embraces diversity, encourages equity, celebrates our differences, and stands up to racism.” This is direct and informative. The documents actually affirms the values of “inclusion,” “community”and “respect” without using those terms. On the other hand, Lewis & Clark’s AR includes the selected terms with the highest frequency amongst the ARs. This AR opens with the following: “In light of heightened concerns on our campus and other campuses around the country, I am writing to reaffirm our commitment to respect and inclusion for everyone in our community.” This is strikingly vague and reveals very little about the true nature of the conversation or the events that motivated the conversation. Although the document uses the terms “inclusion,” “community” and “respect” there is no mention of a target demographic, what their concerns are, or any detailed description of what the University will do to address those concerns. As I engaged in a close-readings of many of these many of ARs and immediately found that it is often impossible to even know what issue is of concern as there is absolutely no details or historical context.
Mark: That’s a great example of the need to toggle between “distant reading” and “close reading.” Word counts and data visualization are great for finding outliers. They are less helpful for understanding texts. How about the student demands? Any outliers? I was stuck by the range in frequency of “black.” It’s not just that ARs don’t use the term. SDs use it at remarkably different rates. It’s over 15% for the Black Liberation Collective and almost 10% for UCLA, but less than 1% for Duke and Brown. The huge number for the BLC is partly an artifact of the document size: it’s only 54 words, and after removing stop words it’s only 31. But that’s not the case with UCLA. What do you think is going on?
TJ: I don’t believe that the low frequency with which university administrations use “Black” (an information-rich, demographic-identifying term) is unique. For instance, the administrations also rarely use specific, topic-appropriate and necessary terms like “color,” “race,” and “racism”. Furthermore, student activists and administrators use the term “Black” as an adjective, modifying various nouns in the demands and responses. “Black students” or “Black organizations” are more specific phrases than “students” and “organizations.” We are more likely to see the latter, broad terms in the administration responses. While in the student demands, we are more likely to see the use of words like “Black” that let readers know the specific demographic at the center of the wave of student activism.
Mark: That’s a great point. I wonder if that lack of specificity is simply a product of “administration speak.” We can assume that most of the university responses were reviewed and edited by multiple contributors, possibly including a “communications office” and some lawyers. That process may have denuded the documents of some original specificity. Or maybe administrators were drawing on some “respond to students” boilerplate?
TJ: Yes, I think a metaphor would be helpful in our understanding of the differences in the word choice of the administrations and student activists. If there was a horrible tornado that ripped through East Washington community in East Point, Georgia and those affected residents wrote letters to the city council describing the effects the storm, we would expect to see the residents use words like “tornado,” “destruction,” “horrible,” “East Washington,” etc. What if the city council responded with broad words and phrases like “weather-related incident” and “our city?” What if the city council never mentioned the East Washington community, the tornado, or the damages? What if the city council only described the initiatives they had already taken to prepare the city of weather-related incidents or merely praised East Point’s new weather task force and commitment to safety. Thus, I feel like the administrations’ avoidance of the word “Black” is very similar to the city council’s lack of using a phrase like “horrible tornado.” This type of indirectness is pervasive in the administrations’ responses. However, when we look at a institution like the University of Oregon, which does not follow the language patterns of most of the other administrations, we see that the “gap” in word usage between the students and administrations is simply one of details. Documents with specific, topic-related terms use words at a similar rate. Documents with nonspecific, dodgy and fluffy language are clustered together. This is likely why Oregon is such an outlier in the scatter plots. We can this in word clouds. I’ll post the word cloud study later, but they also reveal vagueness in administrations’ responses. Word clouds of the student demands are filled with detailed language, while administration responses appear “political correct” and limited in the diversity of words, particularly race-related adjectives and phrases.
It’s not a debate between “Black” or “people of color” or “underrepresented minorities.” It’s a matter of directness versus indirectness. Vagueness versus details.
Mark: Another great point. I makes me wonder how we might measure “vague” versus “specificity.” But there is certainly a boldness in the student language that’s lacking in the administration responses. For example, some of the demands use neologisms such as “latinx” and “latin@” as gender-netural alternative to Latino/Latina. I put “latinx” in the pulldown menus because it was new to me and intriguing. Those terms never appear in administration responses. The example of “latinx” and “latin@” has made me question conventional computational linguistic techniques such as stemming, since that would probably reduce Latino, Latina and Latinx to the root “Latin-.” In our case that technique would denude the texts of their political meaning. The term “latin@” confounds basic text parsing methods because the ampersand is read as punctuation and “cleaned” out of the texts. In fact, even ignoring case seems problematic: there’s certainly a difference between “Black” and “black,” but basic text mining shifts everything to lower case. This project has actually made me leery of using basic text mining packages, or at least the standard methods of “cleaning-up” texts. History is dirty. So where to next?
TJ: How about continuing our work on sentiment analysis?
Mark: Yes, let’s find compare algorithms see what we’ve got in out next post.






 But that’s just an artifact of cancer and heart disease, which kill four times as many Americans as the “runner up,” respiratory diseases.
But that’s just an artifact of cancer and heart disease, which kill four times as many Americans as the “runner up,” respiratory diseases.