
Suppose you would like to control something with many degrees of freedom (engineering parlance for something complicated that has many parts of it that can move or take actions), how would you set up the interface? If it is virtual (like a video dynamic game character) you might use a hand-held controller, if it is a big robot (like an excavator) you might use a series of levers, or if it is software (like a spreadsheet) you might use a big table of buttons (i.e., a keyboard). What these solutions all have in common are that there is one element of the interface that controls one potential action of the device. Pushing right on the joystick makes the character run forward (and nothing else), pulling one lever bends the excavator at the “elbow” only, and one keystroke adds one particular number to one spreadsheet cell. But does it have to be this way?
A favorite scene from the 2002 movie “Minority Report” has a futuristic detective trying to solve a crime under time pressure by looking through vast troves of video segments from different angles and time periods (never mind the metaphysics of Determinism and the Grandfather Paradox for our purposes). But instead of keystrokes, he uses coordinated gestures of his entire body to effortlessly manipulate videographic time and space in blinding speed in a choreography that seemed quintessentially natural – as though it were an extension of walking, sitting, reaching, or grasping. Why isn’t this how we drive cars or play games? The Kinect and Wii track body movement, but mostly map that directly back into the homologous body movement of the video game character – still a one-to-one correspondence.

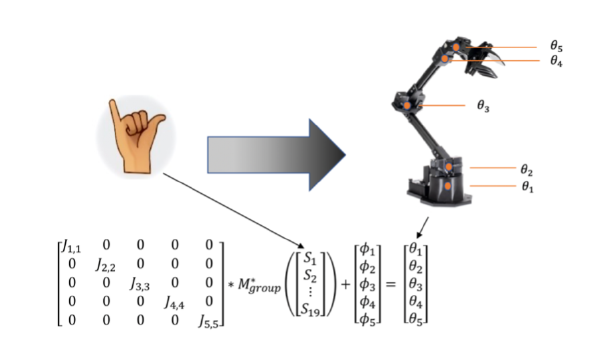
Shifting away from one-to-one (bijective) control isn’t just a question of selling more games or improving construction crew efficiency; this question underlies the key technological hurdle to creating fluidly controlled medical human-machine interfaces, including dexterous prosthetic limbs for amputees and brain-controlled computer terminals for people living with paralysis. To endow a prosthetic arm with dexterous capabilities we need to actuate each of its, say 5, joints, and a bijective correspondence between 5 levers and 5 joints is too slow and cumbersome for what we want to do with the arm and gripper. We want a fluid, natural map between control signals (e.g., contractions of the user’s many muscles in their residual limb) and robot joint movements that is abstract and potentially many-to-one (surjective). The same is true for brain-computer interfaces where we seek a map from the electric twitches of potentially hundreds of individual cortical neurons to the movement of a two or three dimensional computer cursor.
For surjective muscle (myoelectric) control of a prosthetic limb, brain control of a computer, or good old manual control of a physical robot, a big question is how to establish the many-to-one map between user and device. Recent work in our lab led by Steafan Khan tries to settle some controversy in this space, testing how differences in the abstract surjective map affect control performance. In the study, heathy participants controlled a 5 degree-of-freedom robot using articulations of 19 finger joint angles, a many-to-one control problem.

The first map construction method to try was the field’s current favorite: principal components analysis. PCA aggregates example data from the user’s own finger movements and organizes it so the most common combinations control one robot joint, the next most common controls a second robot joint, and so on. Critically, a single finger movement of the user could move all robot joints at once, and many finger movement patters could create the same robot action, making the map abstract and surjective. It could be that because the most common patterns identified by PCA are easier or more natural to make that this makes it harder for users to operate robot degrees of freedom controlled by less common patterns. Thus, the second mapping method to test was PCA modified to find equally common combinations of finger movements and map them accordingly to the robot joints. We can call this egalitarian principal components analysis (EPCA) to emphasize the parity between the frequency of user input patterns mapped to the control of each robot joint. The third method to test was the in vogue machine learning approach that nonlinearly compresses the user’s data examples into common patterns using a nonlinear autoencoder (NLAE), and map them accordingly to the robot joints.
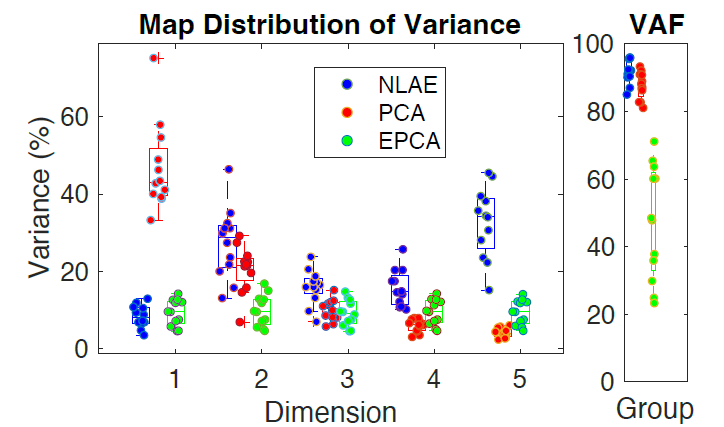
Notably, these three maps (PCA, EPCA, and NLAE) have quite different statistics when it comes to how accurately they can capture the common patterns in the user’s example data. The autoencoder has the highest overall ability to capture the common patterns (i.e., variance accounted for (VAF)) because of its high flexibility, but it distributes the these patterns seemingly randomly to each robot joint for control. PCA, by contrast, has nearly as good pattern capture but organizes the commonality of the discovered patterns in strictly descending order to each subsequent robot joint for control. Lastly, EPCA has poor overall pattern capture but, by design, distributes the commonality of these patterns equally across robot joints for control.
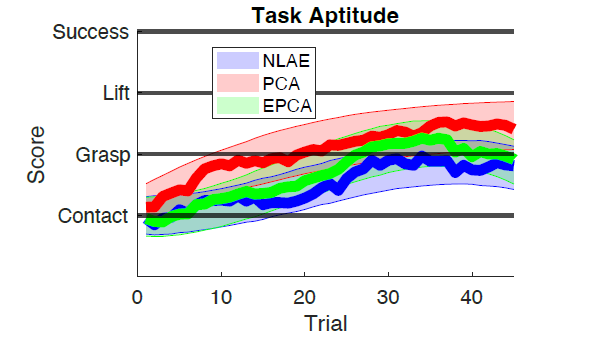
To compare the three highly distinct maps we asked each of the 36 participants to pilot the robot to reach tubes throughout a tabletop workspace, pick them up, and deposit them in a bucket (perhaps something a person with paralysis would do with their brain-controlled, wheelchair-mounted prosthetic limb). What we found was… it didn’t matter what map participants used. Despite the large statistical differences in pattern capture and distribution of pattern commonality to different robot joints, all participants had about the same amount of success learning the surjective robot control task.
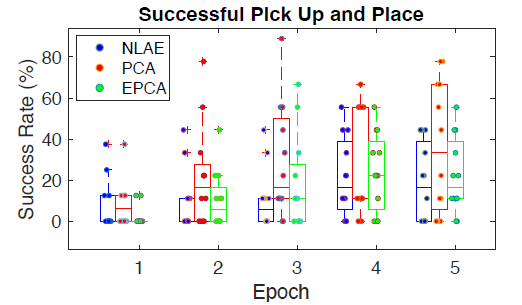
Perhaps the biggest surprise to us was that the spread of participant performances was larger within each map group than between them. That is, the biggest differences in participant performances seemed to be from subjects’ own aptitudes or strategies rather than the maps we constructed for them (browse the manuscript for a long list of things we explored to try and tell the high and low performing participants apart). This suggests to us that the future of research into establishing fluid and naturalistic many-to-one control over robots and other complex devices will be in user learning rather than directly in the interface.
Khan, S. E. and Z. C. Danziger (2023). “Continuous Gesture Control of a Robot Arm: Performance is Robust to a Variety of Hand-to-Robot Maps.” IEEE Transactions on Biomedical Engineering. DOI: 10.1109/TBME.2023.3323601