Taming the Chaos
Category : PROspective
Practical Strategies for Keeping your Research Life Organized
By the time they’ve reached graduate school, every student will have experienced the chaos that sometimes comes with balancing all the tasks needed to thrive in work and in life. In past PROspective articles, Dr. Lauren Christiansen-Lindquist and ADAP Farah Dharamshi have touched on this very topic, offering their own advice about time management and juggling a myriad of different tasks at once.
This short post is meant to provide some inspiration and guidance on elements to consider in shaping an organized and impactful professional life. I will focus on some of the practices I have adopted to keep track of the ever-growing set of tasks an academic researcher can face throughout one’s career.
Academic research disciplines are extremely diverse, and this list of strategies is in no way comprehensive. My intent here is to stimulate some thought on habits, practices, and resources that have helped me, and to point you in a direction that, perhaps, you may not yet have considered.
Folder Structure and Conventions
Like your living or work space, your project space should be kept neat and tidy so that you know where things are when you need them. The projects I undertake typically fall into one of several categories, such as grants, papers, courses, lectures, and presentations. Every category has its own folder. Within each category, every project has its own folder, and each folder has a predetermined structure.
For example, each manuscript has its own folder with the following sub-folders (directories):
- data
- figures
- R
- manuscript
- miscellaneous
Importantly, the organizational structure of each project folder is consistent across all manuscripts that I write. Manuscripts often involve a key set of elements (datasets, codebooks, figures, software code, Microsoft Word or LaTeX documents, etc). In my organizational setup, each element has a predetermined and designated place in the folder, and I know where this place is.
I also rely on a set of file naming conventions that simplify keeping track of where the files are in a given folder. This is especially useful when the number of files in a folder becomes very large. In such a situation, I can easily search for files when I can’t find them. For example, I will often create several versions of a manuscript figure, which can create problems if I’d like to find a specific file. But my figure naming convention allows me to narrow down the number of candidate files to facilitate searching. Here is an example file name for a figure in a recent project:
2020_08_09-PS_Overlap-boxplot-grayscale.pdf
Importantly, my naming convention always employs a date using ISO 8601 date/time formats to avoid confusion over whether “08” is the day or month. With this naming convention, I know the day on which the file was created, what the file is for (propensity score overlap plot), what kind of plot it is (boxplot, instead of density plot, violin plot, or other), and that it’s grayscale. A consistent naming convention like the one above allows me to anticipate where my files are when I can’t immediately find them, or search for them (using, e.g., grep commands) easily.
Version Control
Typically, the elements of a project undergo substantial changes from the time they are created to the time they are completed. Sometimes, making changes is accompanied with a lot of uncertainty: “what if I need something in a previous file version?” This is common with many types of documents, and can eventually lead to an unreadable mess of files (Figure 1). If this scenario sounds familiar to you, you should use version control!

Consider the example of a current team project to demonstrate challenges in using machine learning methods. The initial R program for this project was being written by three research team members, and consisted of ~300 lines of code. It relied heavily on prediction as an example to demonstrate the scientific problems. While this code was being written, the research team decided that an illustration based on causal inference instead of prediction would be clearer. This required completely rewriting most of the code, at the same time that other research team members were still contributing to the main program.
With git and GitHub (version control software program and code sharing platform), I was able to create a branch of the prediction program that I could work on to change everything from prediction to causal inference, and then merge both versions (my new causal inference version, with the team-member updated prediction version) to obtain a final working program for our example. I did all this without duplicating (copying + pasting) any files, all while simultaneously enabling collaborators to contribute to their parts to the program (Figure 2).
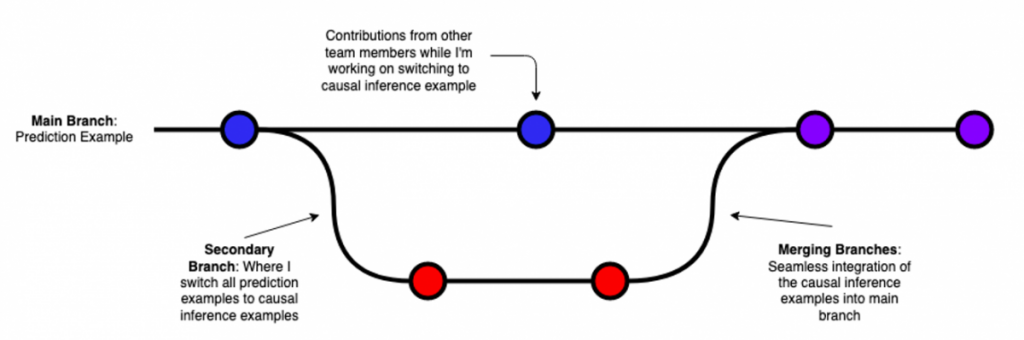
Version control programs such as git make both tracking and merging changes to any document (statistical software program, manuscript, or other) easy. Sharing document versions can easily be done with GitHub. While the learning curve can be steep, my experience has been that it is well worth the investment.
Software
There are innumerable software programs developed to facilitate working with a computer, and it can be daunting to identify those that are useful. Different programs serve different purposes, with a handful devoted to minimizing the time spent handling the keyboard and mouse via workflows and shortcuts. Alfred is one such productivity app for the MacOS system (Windows alternatives include Wox, Listary, or Keypirinha) that makes interacting with the computer a much more productive experience.

For example, using calendar workflows with Alfred enables for easy calendar entries with a few keystrokes, so setting up appointments takes only a few seconds. Alternatively, one can create “snippets” that enable the user to write certain keywords to enter any pre-written text one might desire (see Figure 3 for an example). Given the sheer number of repetitive tasks one can make over the course of a year, streamlining the process of executing these tasks can save you from a lot of repetitive typing!
Planning, Learning, and Training
A final aspect I’m going to discuss on keeping things organized is training. I learned many of the practices mentioned here in Jenny Bryan’s invaluable “What They Forgot to Teach You” short-course, offered at the annual RStudio Conference. I’ve learned many other practices reading books and articles, and taking online short courses. Indeed, in November of every year, I devote a few weeks to researching new software, practices, habits, techniques and ideas on staying organized and productive, and it’s one of the best organizational strategies I’ve adopted.
Staying organized is essential for maintaining productivity. When used well, the strategies covered here can do much to help achieve both goals.
Dr. Ashley Naimi is an Associate Professor in the Department of Epidemiology with expertise in causal inference, machine learning, and artificial intelligence methods. In his research, Dr. Naimi leverages these methods to answer questions related to reproductive and perinatal epidemiology, nutritional epidemiology, social determinants of health.
Email: ashley [dot] naimi [at] emory [dot] edu
Twitter: @ashley_naimi
Join the conversation…
Are you an alumni or current student in the Department of Epidemiology? Do you want to share your professional advice and experiences with a large audience of your peers? We want to hear from YOU! Consider becoming a contributing author for PROspective! To inquire, email your article idea directly to the editors at Confounder [at] emory [dot] edu!
Recent Comments