
Side-by-side view of the scanned document image and OCR text
Are you interested in digital humanities tools but don’t know how to get started? Would you like to engage your students with visualizations from primary source datasets? Were you looking for an opportunity to download and explore primary source data sets? If you answered yes to one or more of these questions, then check out the new Gale database, Digital Scholar Lab. Using this database, you can analyze the Gale digital collections that we have with the help of a suite of DH tools available via this cloud-based platform. To begin playing with the database, please sign in using your Google or Microsoft account.
What does this database offer? With the readily available suite of text mining and visualization tools, researchers will be able to:
- download documents
- gather, clean, curate, and build a corpus of materials for their long-term research
- use text-mining tools to mine a corpus
- work on topic modeling (based on MALLET)
- do a variety of analyses including sentiment, N-grams, and cluster as well as term frequencies
- share their research output with others and
- create visualizations
For example, a search for whisky during the prohibition era yielded approximately 90 results (excluding advertisements). With this data, you can identify parts of speech used by various authors (Figure A).
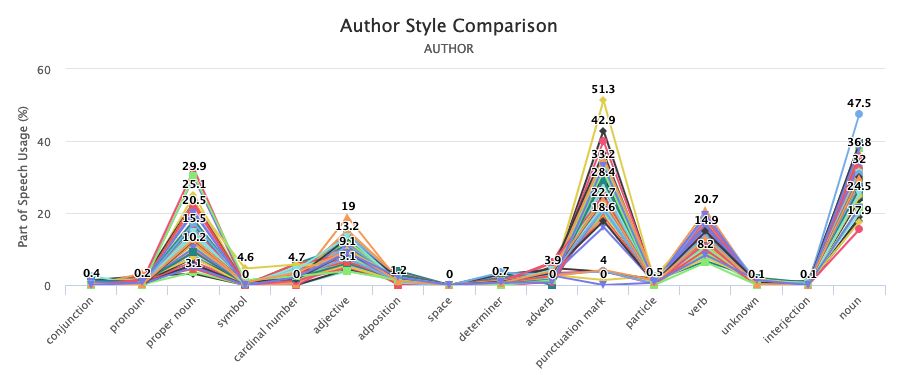
The parts of speech tagger graph, displayed here, measures which parts of speech appear more frequently for specific authors.
You can run a sentiment analysis to determine the tone—whether negative or positive—of groups of documents (Figure B).

This sentiment analysis graph attempts to model the tone–whether positive or negative–of our document collection.
Gale has an excellent webinar that will help you get started. Other relevant video clips are also available on their YouTube channel.