Sorry for the delay on my blog post! I’ve finally managed to figure out the coding to search for all inflections of the various nostra/mea epithets in Latin documents. I was having trouble using .*? to account for varying numbers of characters between nostra/mea and its accompanying noun (e.g. nostra clementia), as R was, despite the “?”, still being far too greedy. str_locate_all showed that it was pairing nostra‘s and titles that were thousands of characters apart!
My solution has been to ask R to search for combinations of nostra/mea and the accompanying noun with anywhere from 0 to 80 characters inbetween. Furthermore, I’ve simplified my code by only searching for the parts of these words that don’t inflect. So, for example, I wrote:
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}clementia.{0,80}|clementia.{0,80}nostra.{0,80}|mea.{0,80}clementia.{0,80}|clementia.{0,80}mea.{0,80}”) #CLEMENTIA
This accounts for all inflections; it turns up nostra/mea clementia, nostrae/meae clementiae, and nostram/meam clementiam. I did this for all of the imperial epithets that I have identified within the Theodosian Code. I then used those results to locate and read each instance in the Latin text, both so as to confirm their use as imperial epithets within their respective contexts, and so as to record their exact location within the Code. It’s been time consuming, but very rewarding. I now have complete and accurate results for their frequency within the Code:
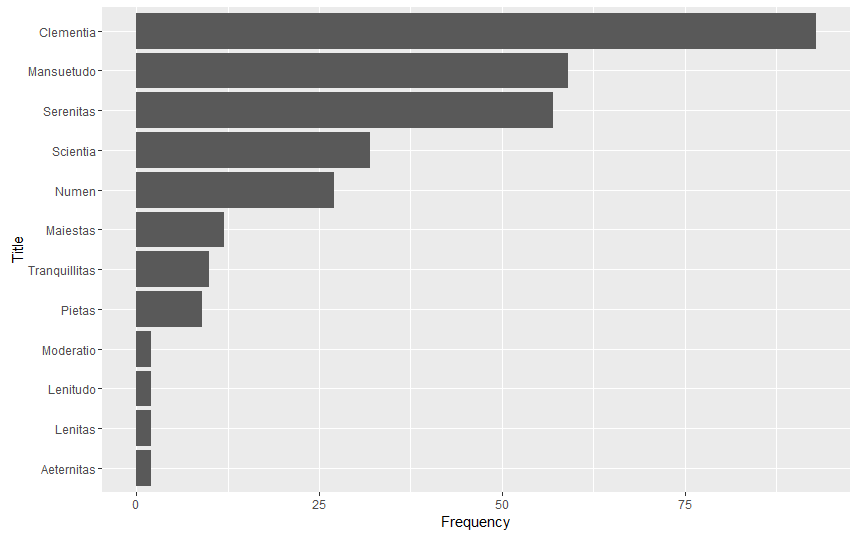
Now that I have an effective formula down, I will run through the rest of my documents this week: the main ones are the Code of Justinian, Symmachus’ Relationes to the emperors, and a series of Latin Panegyrics. I hope to have a few of these done before class on Thursday; I’ll update this post with those results.
My code
#THEODOSIAN CODE
CTh.scan <- scan(“~/Education/Emory/Coursework/Digital Humanities Methods/Project/Theodosian Code Raw Text.txt”,
what=”character”, sep=”\n”)
CTh.df <- data.frame(CTh.scan, stringsAsFactors=FALSE)
CTh.df <- str_replace_all(string = CTh.df$CTh.scan, pattern = “[:punct:]”, replacement = “”)
CTh.df <- data.frame(CTh.df, stringsAsFactors = FALSE)
CTh.lines <- tolower(CTh.df[,1])
book.headings <- grep(“book”, CTh.lines)
start.lines <- book.headings + 1
end.lines <- book.headings[2:length(book.headings)] – 1
end.lines <- c(end.lines, length(CTh.lines))
CTh.df <- data.frame(“start” = start.lines, “end”=end.lines, “text”=NA)
i <- 1
for (i in 1:length(CTh.df$end))
{CTh.df$text[i] <- paste(CTh.lines[CTh.df$start[i]:CTh.df$end[i]], collapse = ” “)}
CTh.df$Book <- seq.int(nrow(CTh.df))
#String Extracts of Imperial Titles
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}aeternita.{0,80}|aeternita.{0,80}nostra.{0,80}|mea.{0,80}aeternita.{0,80}|aeternita.{0,80}mea.{0,80}”) #AETERNITAS
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}clementia.{0,80}|clementia.{0,80}nostra.{0,80}|mea.{0,80}clementia.{0,80}|clementia.{0,80}mea.{0,80}”) #CLEMENTIA
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}lenita.{0,80}|lenita.{0,80}nostra.{0,80}|mea.{0,80}lenita.{0,80}|lenita.{0,80}mea.{0,80}”) #LENITAS
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}lenitud.{0,80}|lenitud.{0,80}nostra.{0,80}|mea.{0,80}lenitud.{0,80}|lenitud.{0,80}mea.{0,80}”) #LENITUDO
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}maiesta.{0,80}|maiesta.{0,80}nostra.{0,80}|mea.{0,80}maiesta.{0,80}|maiesta.{0,80}mea.{0,80}”) #MAIESTAS
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}mansuetud.{0,80}|mansuetud.{0,80}nostra.{0,80}|mea.{0,80}mansuetud.{0,80}|mansuetud.{0,80}mea.{0,80}”) #MANSUETUDO
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}moderatio.{0,80}|moderatio.{0,80}nostra.{0,80}|mea.{0,80}moderatio.{0,80}|moderatio.{0,80}mea.{0,80}”) #MODERATIO
str_extract_all(string = CTh.df$text, pattern = “nostrum.{0,80}numen.{0,80}|numen.{0,80}nostrum.{0,80}|nostr.{0,80}numin.{0,80}|numin.{0,80}nostr.{0,80}|meum.{0,80}numen.{0,80}|numen.{0,80}meum.{0,80}|me.{0,80}numin.{0,80}|numin.{0,80}me.{0,80}”) #NUMEN
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}perennita.{0,80}|perennita.{0,80}nostra.{0,80}|mea.{0,80}perennita.{0,80}|perennita.{0,80}mea.{0,80}”) #PERENNITAS
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}pieta.{0,80}|pieta.{0,80}nostra.{0,80}|mea.{0,80}pieta.{0,80}|pieta.{0,80}mea.{0,80}”) #PIETAS
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}scientia.{0,80}|scientia.{0,80}nostra.{0,80}|mea.{0,80}scientia.{0,80}|scientia.{0,80}mea.{0,80}”) #SCIENTIA
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}serenita.{0,80}|serenita.{0,80}nostra.{0,80}|mea.{0,80}serenita.{0,80}|serenita.{0,80}mea.{0,80}”) #SERENITAS
str_extract_all(string = CTh.df$text, pattern = “nostra.{0,80}tranquillita.{0,80}|tranquillita.{0,80}nostra.{0,80}|mea.{0,80}tranquillita.{0,80}|tranquillita.{0,80}mea.{0,80}”) #TRANQUILLITAS
#Imperial Title Sums
aeternitas <- 2
clementia <- 93
lenitas <- 2
lenitudo <- 2
maiestas <- 12
mansuetudo <- 59
moderatio <- 2
numen <- 27
perennitas <- 12
pietas <- 9
scientia <- 32
serenitas <- 57
tranquillitas <- 10
#Imperial Title Sum Graph
Frequency <- c(clementia, mansuetudo, serenitas, scientia, numen, maiestas, tranquillitas, pietas, aeternitas, lenitas, lenitudo, moderatio)
Title <- c(“Clementia”, “Mansuetudo”, “Serenitas”, “Scientia”, “Numen”, “Maiestas”, “Tranquillitas”, “Pietas”, “Aeternitas”, “Lenitas”, “Lenitudo”, “Moderatio”)
sum.df <- cbind.data.frame(Title, Frequency)
sum.df$Title <- factor(sum.df$Title, levels = sum.df$Title[order(sum.df$Frequency)]) #Reorders dataframe based on Frequency
ggplot(data=sum.df, aes(x=Title, Frequency), y=Frequency) + geom_bar(stat = “identity”) + coord_flip() #Word Total Graph
Index of Imperial Epithets in the Theodosian Code
Nostra Aeternitas
10.22.3
Mea Aeternitas
12.1.160
Nostra Clementia
1.1.5
1.7.4
1.14.1
2.6.1
2.8.20
2.23.1
5.1.2
5.2.1
5.15.21
5.16.31
6.2.26
6.4.18
6.4.33
6.23.4
6.30.4
6.35.14
7.1.16
7.1.17
7.4.21
7.4.25
7.6.5
7.13.13
7.21.4
8.5.1
8.5.5
8.5.30
8.5.44
8.5.50
8.5.54
8.5.56
8.5.57
8.10.3
9.16.12
9.17.2
9.21.6
9.34.7
9.40.16
9.40.16
9.41.1
9.45.4
10.1.16
10.10.26
10.10.32
10.10.34
10.14.1
10.15.2
11.7.15
11.16.7
11.16.8
11.20.4
11.28.3
11.28.14
11.30.13
11.30.54
11.30.57
11.30.61
11.36.24
12.1.14
12.1.14
12.1.15
12.1.146
12.1.169
12.1.184
12.6.30
12.10.1
12.12.4
12.12.14
13.1.20
13.3.17
14.10.3
14.15.5
14.17.5
14.17.14
15.1.44
15.1.49
15.3.4
15.6.1
16.1.2
16.2.42
16.3.2
16.5.46
16.5.49
16.5.54
16.5.54
16.5.60
16.5.63
16.8.17
16.11.2
Mea Clementia
1.8.2
1.8.3
6.26.17
7.16.2
11.20.5
Nostra Lenitas
1.22.2
10.8.3
Nostra Lenitudo
8.12.6
15.1.5
Nostra Maiestas
6.21.1
6.27.17
6.27.17
8.4.26
8.5.39
11.29.1
11.30.66
11.30.68
13.3.18
14.3.18
15.1.47
16.10.20
Nostra Mansuetudo
1.2.8
1.5.9
1.10.1
1.15.8
1.28.1
3.9.1
4.14.1
6.2.19
6.22.8
6.23.4
6.30.18
6.30.20
7.13.9
8.5.12
8.5.22
8.5.54
8.5.58
8.8.2
8.10.2
9.16.10
9.30.2
10.7.2
10.7.2
10.9.2
10.9.3
10.10.20
10.16.2
11.7.21
11.12.4
11.16.11
11.16.14
11.28.3
11.28.5
11.30.32
11.30.41
11.30.41
12.6.5
12.6.12
12.6.28
12.12.5
12.12.10
12.12.10
12.19.3
13.3.4
13.5.38
13.6.5
14.1.2
14.4.3
14.9.1
15.3.1
15.5.5
15.7.4
15.7.6
15.7.9
16.2.12
16.5.7
16.5.38
16.10.2
Mea Mansuetudo
12.1.121
Nostra Moderatio
6.30.24
8.18.3
Nostrum Numen
1.2.12
1.9.2
2.23.1
2.33.4
5.12.3
5.12.3
6.4.29
6.4.32
6.5.2
6.14.3
6.23.3
6.30.15
7.7.4
7.8.3
8.1.13
8.5.40
8.5.62
9.40.11
11.21.3
11.28.15
11.30.49
12.12.7
15.4.1
15.5.5
16.4.4
16.8.13
Meum Numen
11.1.33
Nostra Perennitas
1.1.5
2.4.4
4.4.5
5.15.18
7.7.4
9.19.3
9.38.8
10.20.10
12.12.9
13.5.12
15.1.31
Mea Perennitas
6.30.21
Nostra Pietas
5.12.3
6.10.1
10.26.1
11.1.34
11.1.36
13.1.21
14.26.2
15.1.37
Mea Pietas
14.16.2
Nostra Serenitas
1.1.2
1.12.5
1.22.2
2.16.2
4.4.3
5.13.2
5.16.31
6.8.1
6.22.3
6.23.1
6.26.13
6.27.8
6.29.3
6.30.17
7.1.17
7.8.10
8.5.14
8.5.22
8.5.32
8.5.45
8.5.48
8.5.56
8.7.16
9.19.3
9.38.6
9.38.9
9.40.7
9.40.20
9.42.14
9.42.19
9.42.20
10.10.11
11.2.5
11.16.20
11.28.4
11.30.47
11.30.56
11.30.64
11.31.9
11.31.9
12.13.6
13.10.8
14.2.1
14.4.8
15.1.11
15.1.26
15.1.42
15.1.51
15.5.5
15.7.6
15.7.6
16.2.37
16.5.12
16.5.14
16.8.22
16.11.3
Mea Serenitas
11.20.5
Nostra Scientia
1.1.5
1.5.1
1.15.2
1.16.6
1.29.1
2.18.1
6.4.21
7.1.12
8.5.25
9.1.1
9.1.13
9.4.1
9.21.1
9.34.3
10.8.3
11.7.16
11.16.8
11.16.8
11.29.2
11.30.1
11.30.1
11.30.9
11.30.18
11.30.18
11.37.1
12.1.1
12.12.3
15.1.2
15.1.2
15.1.30
16.10.1
16.10.15
Nostra Tranquillitas
1.2.10
1.6.4
5.15.18
6.4.31
6.12.1
8.7.16
11.30.31
16.1.4
16.2.15
16.4.1