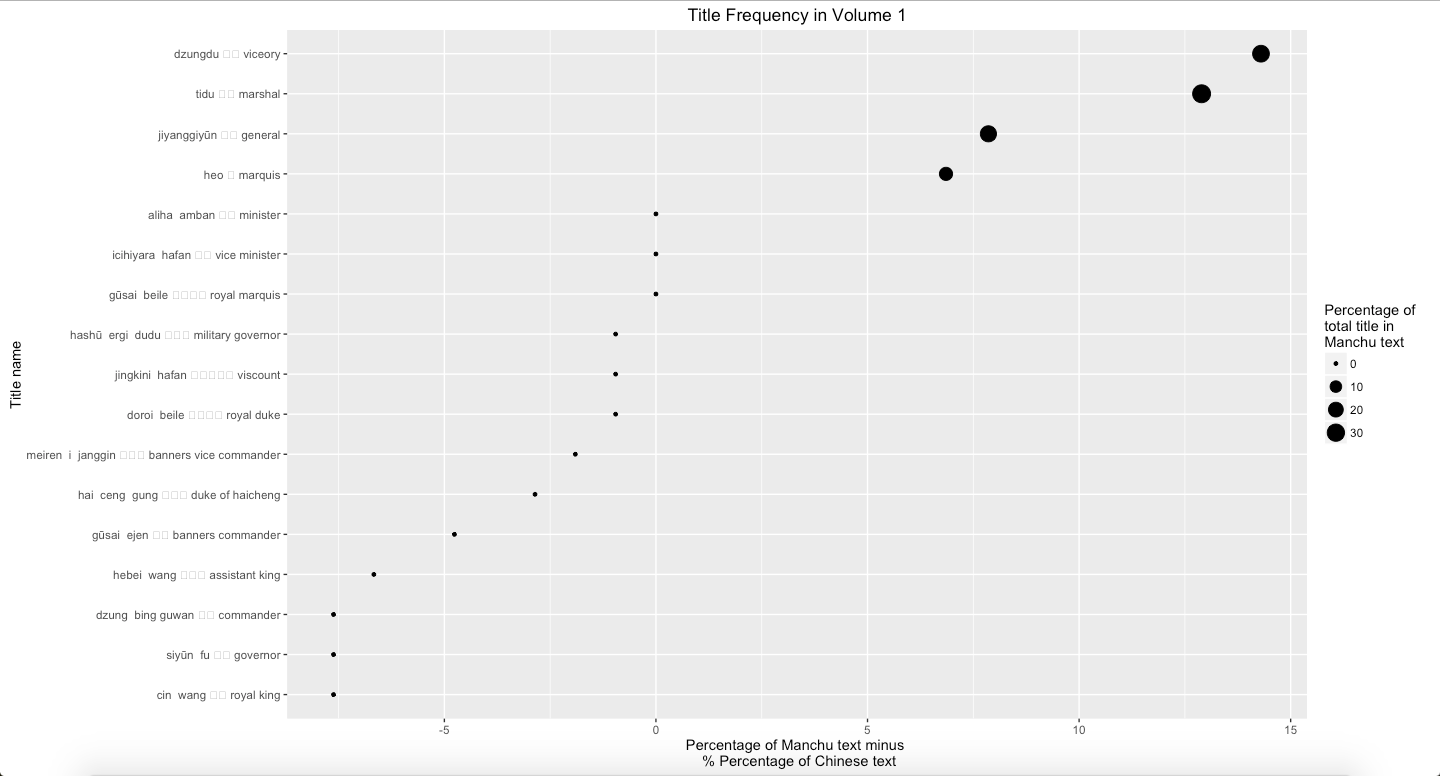
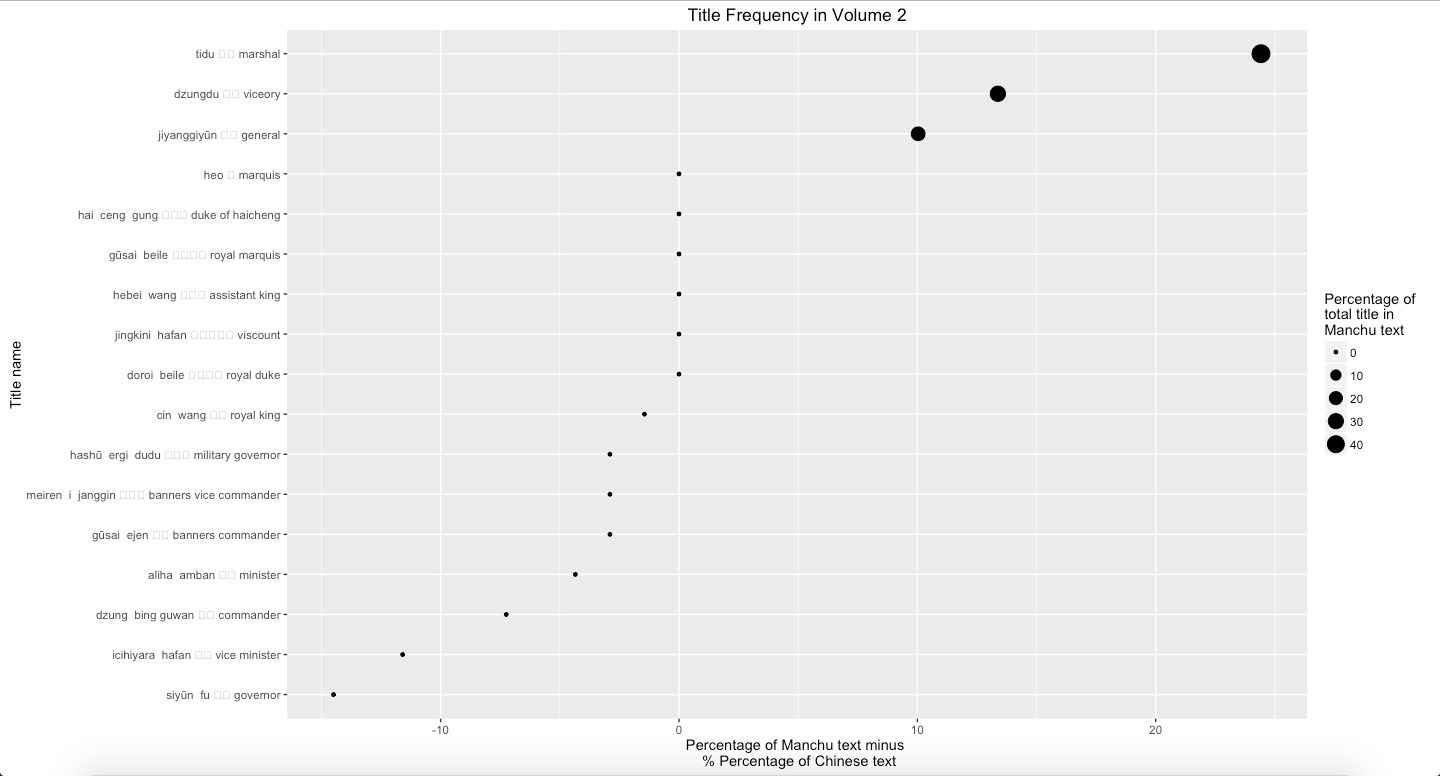
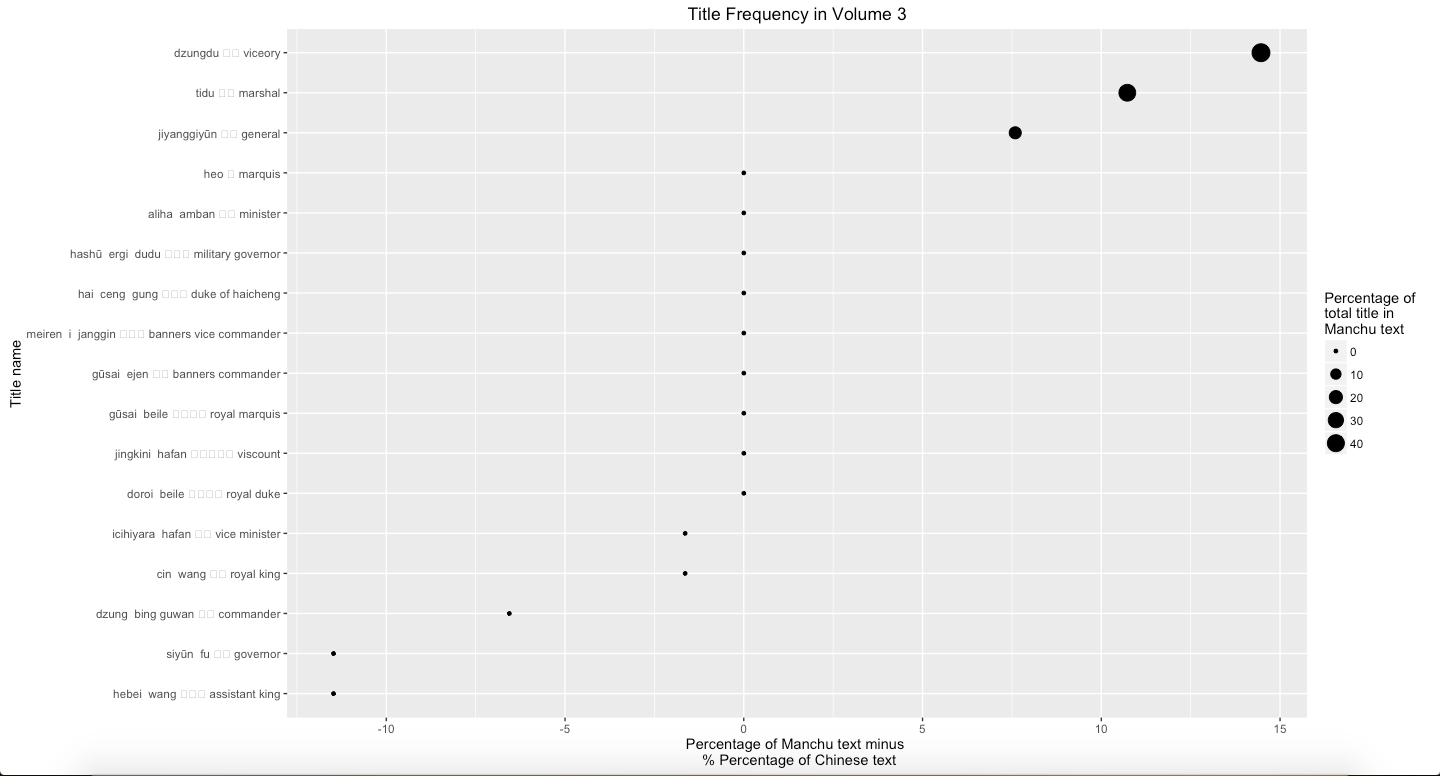
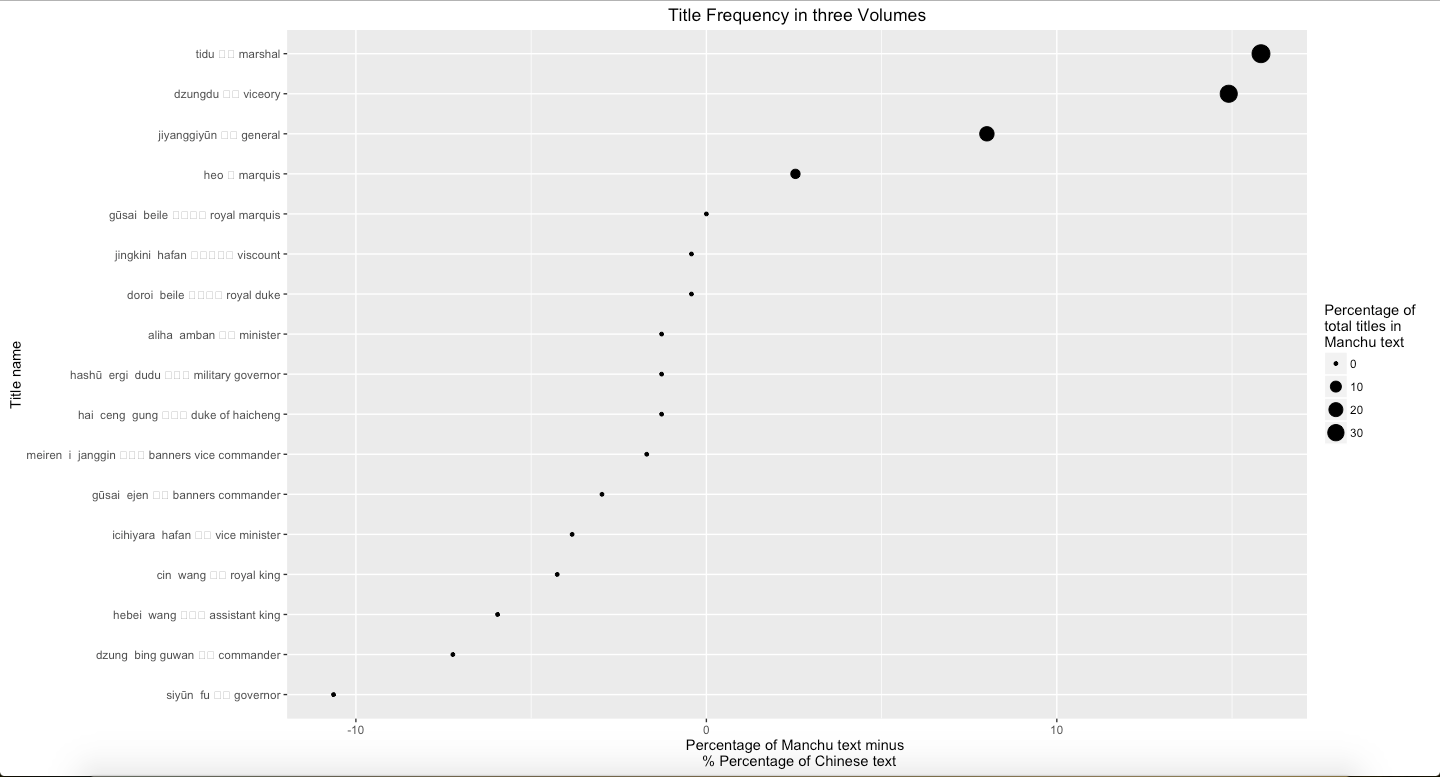
A Short Introduction of Natsume Soseki

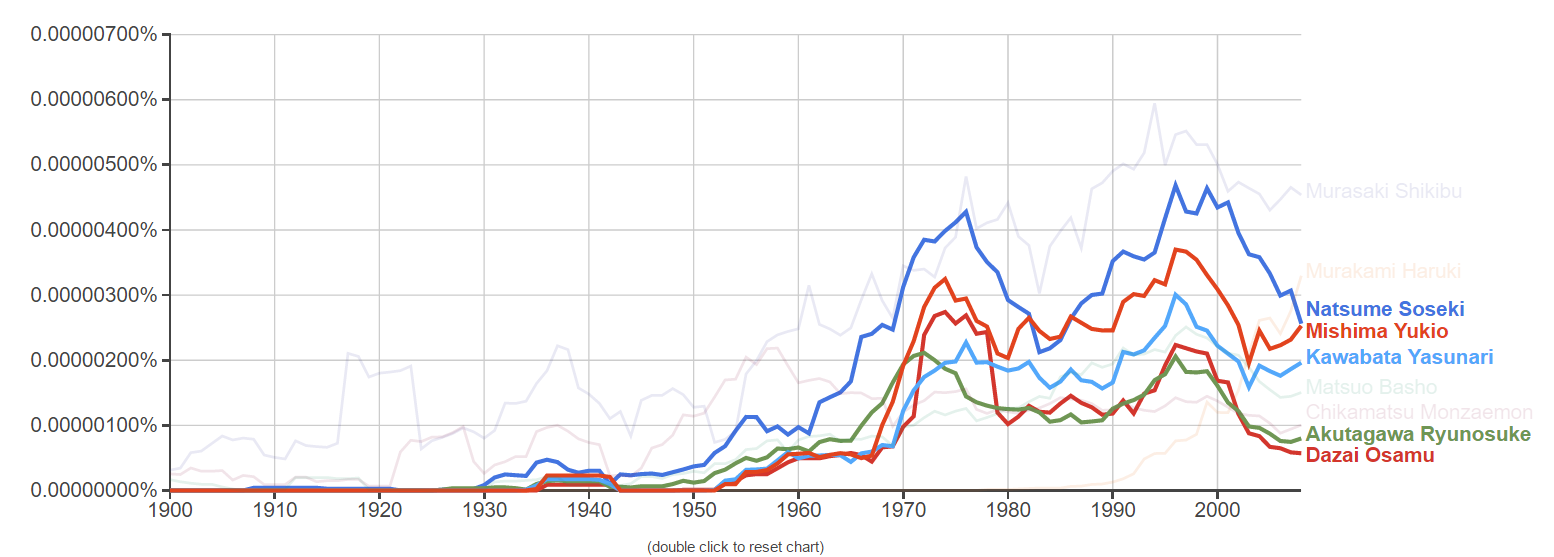
Natsume Soseki, born in 1867, the year before the Meiji Restoration, was a Japanese author whose works characterized the perplexity of Japanese during the era of rapid westernization. He loved Chinese literature, but studying English was a fashion at his time. Therefore, he became a scholar in English literature. The Japanese government sent him to study in England from 1901 to 1903, but this became his most unpleasant years. Soseki became mad in London, and started to question the idea of modernity. He was aware of the superficiality of Japanese westernization and aimless imitation of the west. In his works, he mainly focused on the pain and solitude that modernity brought to Japanese. Between 1905 and 1916, he wrote fifteen novels, including one unfinished. In 1907, Soseki rejected his professorship and started to work for Asahi newspaper, where most of his works were published. In 1916, he died of stomach ulcer.
Update on Historiographical Research
This is an update on last post. Natsume Soseki is commonly referred by his given name (or rather pen name), Soseki, so searching for “Soseki” in DfR of JSTOR collections is more accurate.
Text Mining of Soseki’s Novels
The central question that I am asking is what issues on modernity and tradition did Soseki write about and was Soseki more inclined to the traditional side or modern side.
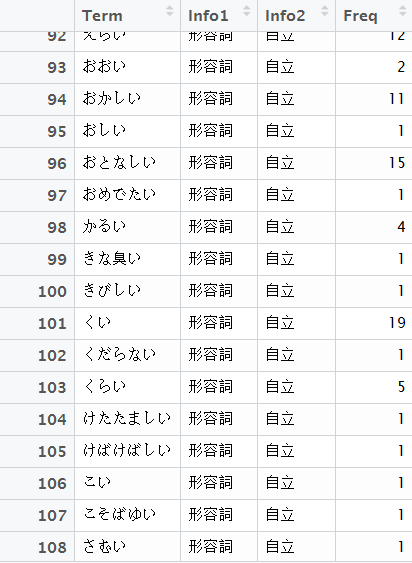
The Japanese tokenizer MeCab with IPA dictionary takes in a txt file and produces a dataframe like the following graph. Term column is the word. Info1 is part of speech. Info2 is more information on part of speech.
 I processed the txt files with the same code I did a month ago, taking out pronunciation guide and style annotations. Then, I used dataframes generated by MeCab to calculate the term frequency in percentage and tf-idf. For all the graphs, the novels names on the axes are in chronological order
I processed the txt files with the same code I did a month ago, taking out pronunciation guide and style annotations. Then, I used dataframes generated by MeCab to calculate the term frequency in percentage and tf-idf. For all the graphs, the novels names on the axes are in chronological order
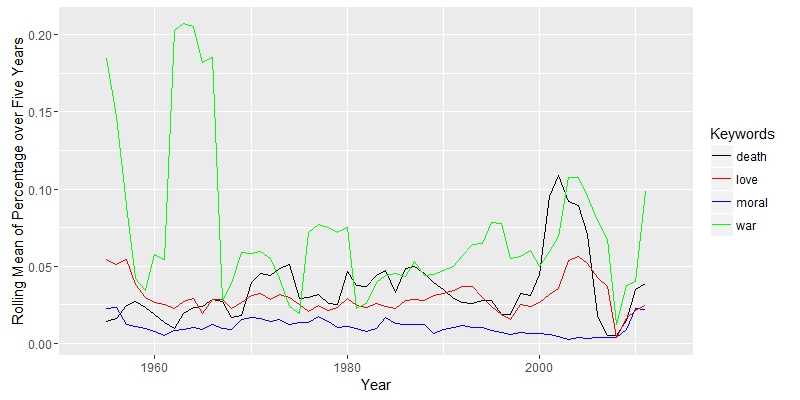
First, I focused on term frequency of some keywords. In last post I mentioned that English scholars were interested in discussion wars in studies of Japanese literature. This interests are not unjustified, since most of Soseki’s works mentioned words related to military and war. Meiji Japan was also a time of military victories, like Sino-Japanese War (1894-95) and Russo-Japanese War (1904-05). These were directly related to the westernization of Japan.
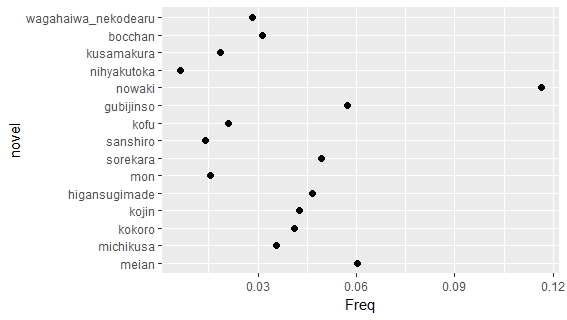
Nevertheless, the word related to war was not that common compared to words related to love or death. In some of the works, Soseki showed his idea on love and solitude in modern world and how marriage in the new era should be different from old time. Maybe scholars should pay more attention to these issues.
For the other question, how did Soseki place himself in modernity and tradition. Although some famous critic, like Eto Jun thinks that Soseki stands on the side of tradition, especially in his last several works, more scholars argue that Soseki stands on side of modernity. Soseki was aware of the pain brought by westernization to Japanese, but he did not deny it. In some of his essays, he justified Japanese colonization of Manchuria and Korea by commenting that this was an inevitable result of a modernizing Japan.
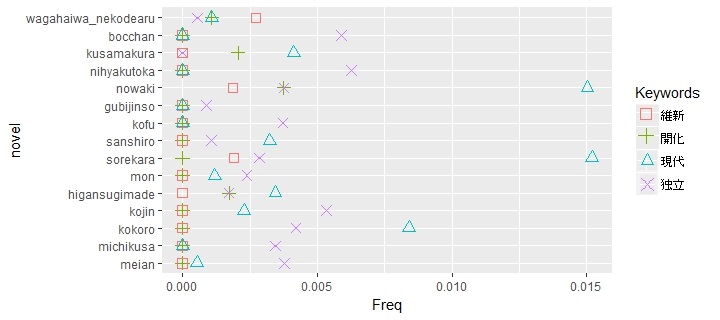
The following figure presents frequency of four words, restoration (維新), enlightenment (開化), modernity (現代) and independent (独立), directly related to modernity and Meiji Restoration, in his novels. All of the novels used at least one of the four words.
 The following graph is a comparison between the frequencies the word modernity (現代) and antiquity (古代).Soseki used a lot more modernity than antiquity. I wanted to find the frequency of tradition (伝統) or national learning (国学), but it turned out that Soseki never used these words.
The following graph is a comparison between the frequencies the word modernity (現代) and antiquity (古代).Soseki used a lot more modernity than antiquity. I wanted to find the frequency of tradition (伝統) or national learning (国学), but it turned out that Soseki never used these words.
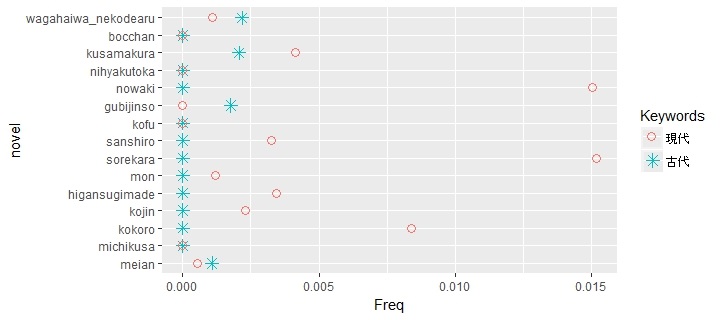 It might be the case that words like tradition or national learning emphasize superiority of Japanese culture, so Soseki avoided using them. His was disgusted by shallow nationalist movement of his classmates when he was young. By contrast the word Chinese study appeared several time in his novels.
It might be the case that words like tradition or national learning emphasize superiority of Japanese culture, so Soseki avoided using them. His was disgusted by shallow nationalist movement of his classmates when he was young. By contrast the word Chinese study appeared several time in his novels.
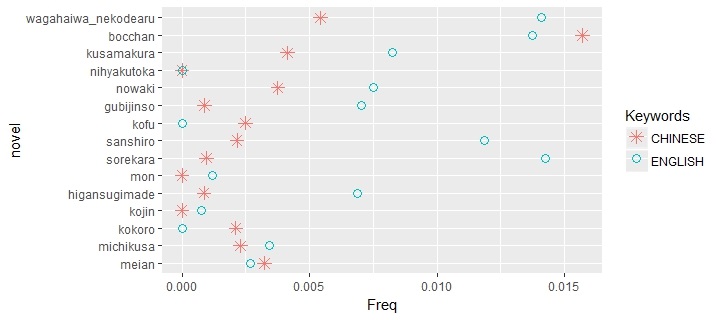
Another way of looking at the question is to search for the words related to Chinese and English. For Soseki, Chinese is the more traditional culture and English is more modern, while the westernizing Japan is somewhere between modernity and tradition. Related words to Chinese include Qing Empire (清国), Japan-Qing (日清), China (中国), Chinese book (漢籍), Chinese land (漢土) and Chinese poetry (漢詩); related words to English include the UK (イギリス or 英国), English (英語 or 英文), Anglo-Japanese (英和) and English translation (英訳)
This graph is not as extreme as last one. Although words related to English is still more important, words related to Chinese appear a lot.
 Tf-idf
Tf-idf
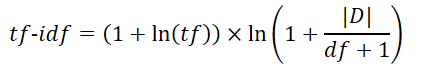
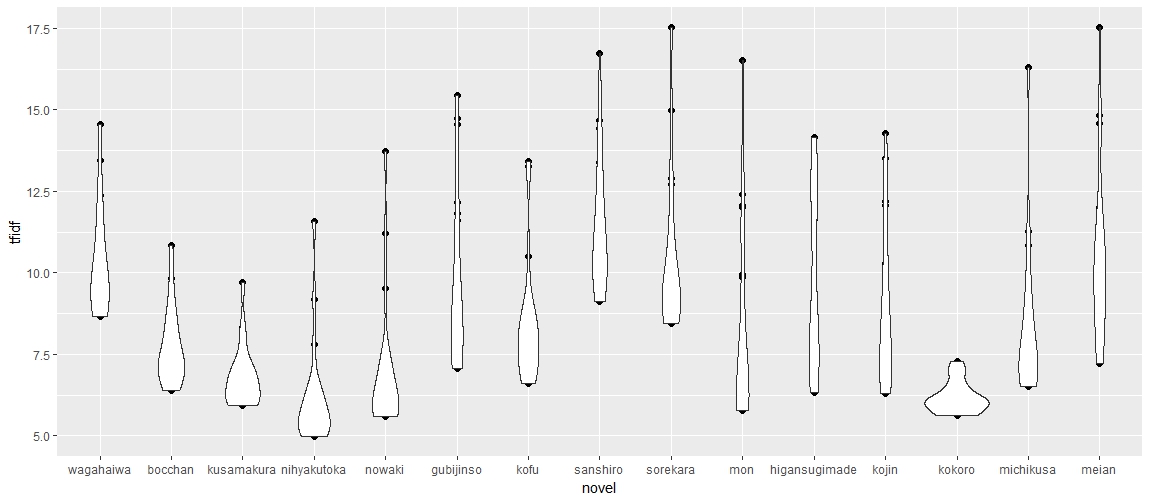
The above equation is what I used for tf-idf. Both term frequency and document frequency are normalized.
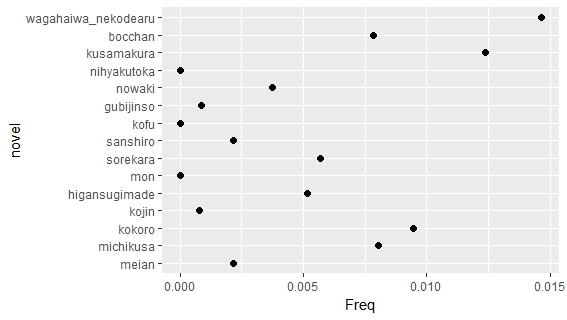
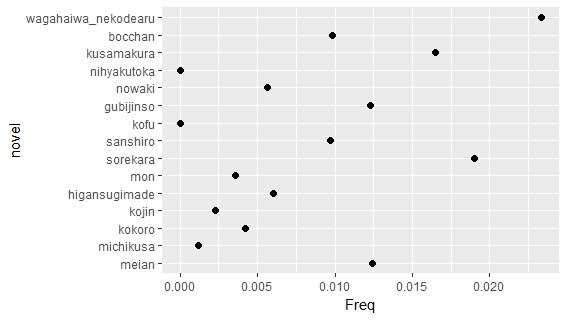
Some of the novels are more interesting than other. Kokoro (The Hearts) is one of Soseki’s most beloved novel. The following graph is the top 5 words by tf-idf for each novel. Kokoro has the lowest tf-idf index, because it does not use many uncommon word. In other novels, characters has names, so the names have high tf-idf index. However, Soseki is reluctant to give characters names in Kokoro, so the most distinctive word is Zoshigaya (雑司ヶ谷), which is a place name in Tokyo.
Edwin McClellan, who introduced Soseki to western audience and translated two of Soseki’s novels, comments that Soseki wrote Kokoro as an “allegory of sorts”. Isolation and pain of Sensei, the protagonist in Volumn 3 of Kokoro, could be troubles to any Meiji intellectuals. The work is not only stylistically simple as noted by McClellan, but also lexically simple as shown in following graphs.
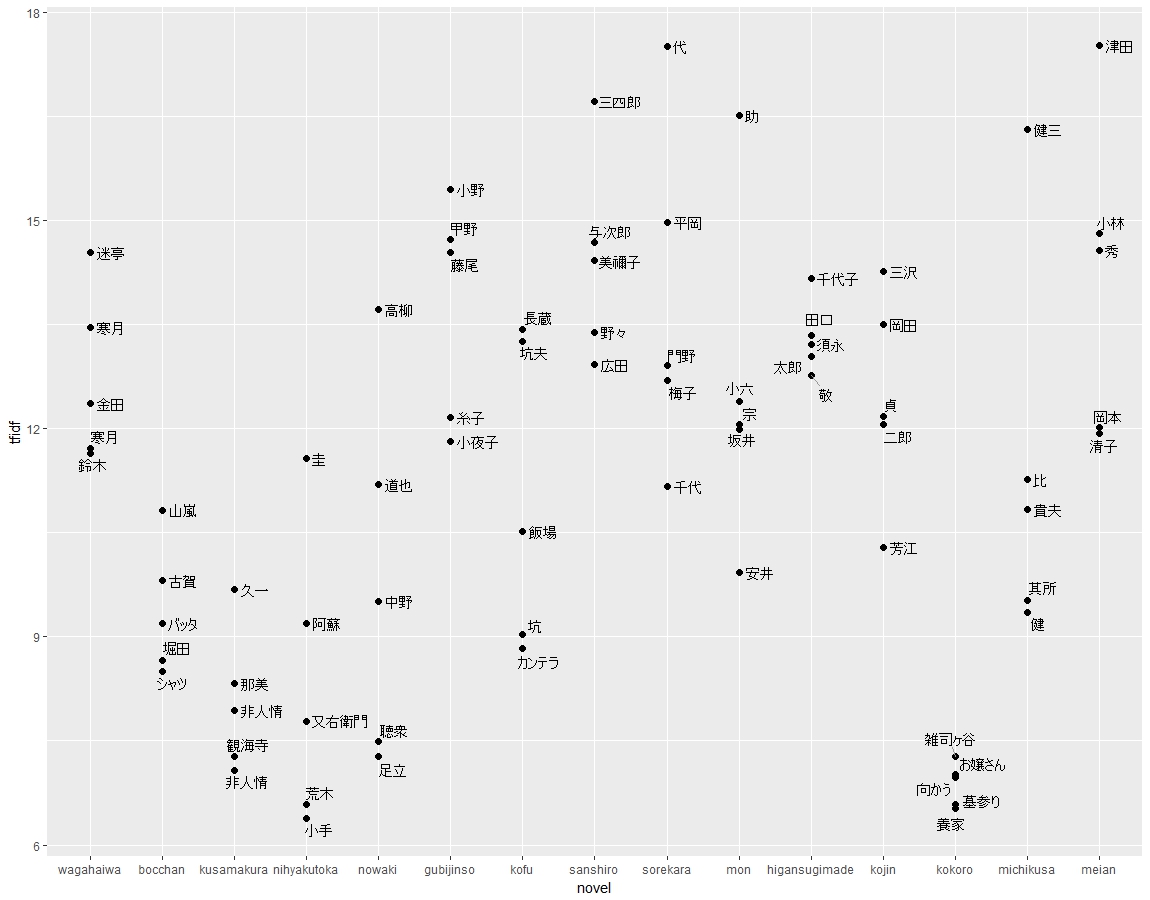 A violin graph of top 20 words by tf-idf also shows that Kokoro tends to use common word.
A violin graph of top 20 words by tf-idf also shows that Kokoro tends to use common word.
 Code
Code
### Text Processing code is in the post about Dazai Osamu
### Make frequency tables with RMeCab
Sys.setlocale(“LC_ALL”, “Japanese”) ### Windows users may want to use this to avoid encoding problems
library(RMeCab) ### Japanese Tokenizer
na.zzz <- RMeCabFreq(“D:/Google Drive/JPN_LIT/Natsume/zzz.txt”)
na.zzz.reduced <- na.zzz[which(na.zzz$Info1 != “記号”),] ###Take out punctuations
files.cle.dir<- list.files(“D:/Google Drive/JPN_LIT/Natsume/cleaned”)
for (n.i in 1:length(files.cle.dir)){
assign(paste0(“n.”, files.cle.dir[n.i]), RMeCabFreq(paste0(“D:/Google Drive/JPN_LIT/Natsume/cleaned/”,files.cle.dir[n.i]))[which(RMeCabFreq(paste0(“D:/Google Drive/JPN_LIT/Natsume/cleaned/”,files.cle.dir[n.i]))$Info1 != “記号”),])
}
###A sample code of combining frequency table of a novel to the frequency table of the corpus of fifteen novels.
z <- 1
y <- 1
while (z <= length(na.zzz.reduced$Term)){
if(n.bocchan.txt$Term[y] == na.zzz.reduced$Term[z] & n.bocchan.txt$Info1[y] == na.zzz.reduced$Info1[z] & n.bocchan.txt$Info2[y] == na.zzz.reduced$Info2[z]){
na.zzz.reduced$bocchan[z] <- n.bocchan.txt$Freq[y]
y <- y + 1
}
z <- z + 1
}
### na.zzz.reduced is the final frequency dataframe with every novel
### Tf-idf
n.TMD <- na.zzz.reduced[,4:19]
n.TMD$Dfreq <- apply(n.TMD, 1, function(x) length(which(x != 0)))
n.TMD$Dfnorm <- log(15/n.TMD$Dfreq +1)
n.TFIDF.df <- data.frame(t(apply(n.TMD[,2:16], 1, function(x) log(x)+1)))
n.TFIDF.df <- n.TFIDF.df*n.TMD$Dfnorm
n.TFIDF.df[n.TFIDF.df == -Inf] <- 0
Final.TFIDF.df <- cbind(na.zzz.reduced[,1:3],n.TFIDF.df)
##### Make another table of Final percentage
n.PERC.df<- data.frame(apply(n.TMD[,1:16], 2,function(x) x/sum(x)*100))
Final.PERC.df <- cbind(na.zzz.reduced[,1:3],n.PERC.df)
###Make a dataframe of top 20 and top 5 tfidf for each novel and change the name of wagahaiwa_nekodearu since it is too long
all.TFIDF20 <- data.frame(Term = NA,tfidf = NA, novel = NA)
for (col.i in 4:18){
all.TFIDF20 <- rbindlist(list(all.TFIDF20, cbind(Final.TFIDF.df[order(-Final.TFIDF.df[,col.i]),][1:20,][,c(1,col.i)],colnames(Final.TFIDF.df)[col.i])))
}
all.TFIDF20 <- all.TFIDF20[-1,]
all.TFIDF20$novel <- as.character(all.TFIDF20$novel)
all.TFIDF20[all.TFIDF20 == “wagahaiwa_nekodearu”] <- “wagahaiwa”
### Top5 tf-idf
all.TFIDF5 <- data.frame(Term = NA,tfidf = NA, novel = NA)
for (col.i in 4:18){
all.TFIDF5 <- rbindlist(list(all.TFIDF5, cbind(Final.TFIDF.df[order(-Final.TFIDF.df[,col.i]),][1:5,][,c(1,col.i)],as.character(colnames(Final.TFIDF.df)[col.i]))))
}
all.TFIDF5 <- all.TFIDF5[-1,]
all.TFIDF5$novel <- as.character(all.TFIDF5$novel)
### Violin Graph
ggplot(all.TFIDF20, aes(x = novel, y = tfidf))+
geom_point(size = 2) +
scale_x_discrete(limits=c(“wagahaiwa”,”bocchan”,”kusamakura”,”nihyakutoka”,”nowaki”,”gubijinso”,”kofu”,”sanshiro”,”sorekara”,”mon”,”higansugimade”,”kojin”,”kokoro”,”michikusa”,”meian”)) +
geom_violin()
### Top 5 tf-idf with term shown
library(ggrepel) ### An extension to ggplot2 to avoid overlap of terms in graph
ggplot(all.TFIDF5, aes(x = novel, y = tfidf))+
geom_point(size = 2) +
scale_x_discrete(limits=c(“wagahaiwa”,”bocchan”,”kusamakura”,”nihyakutoka”,”nowaki”,”gubijinso”,”kofu”,”sanshiro”,”sorekara”,”mon”,”higansugimade”,”kojin”,”kokoro”,”michikusa”,”meian”)) +
geom_text_repel(aes(label=Term), size =4, segment.color = ‘grey60’,nudge_x =0.05)
### A sample graph of how I made the table for words related to Chinese and English. All other frequency graphs are similar (I admit that I used Mspaint to change some of the legend, because it is more convenient)
chn.all.PERC.df <- Final.PERC.df[which(Final.PERC.df$Term == “清国” |
Final.PERC.df$Term == “中国”|
Final.PERC.df$Term == “漢学”|
Final.PERC.df$Term ==”漢語”|
Final.PERC.df$Term ==”漢詩”|
Final.PERC.df$Term ==”漢籍”|
Final.PERC.df$Term ==”漢土”|
Final.PERC.df$Term ==”漢”|
Final.PERC.df$Term ==”漢人”),] ### I choose the terms based on search for three words, “清”, “漢” and “中国”.
eng.all.PERC.df <- Final.PERC.df[which(Final.PERC.df$Term == “イギリス” |
Final.PERC.df$Term == “英国”|
Final.PERC.df$Term == “英訳”|
Final.PERC.df$Term ==”英語”|
Final.PERC.df$Term ==”英文”|
Final.PERC.df$Term ==”英和”),]### The choice of vocabularies is similarly determined by the research intention
chn.eng.df <- data.frame(apply(chn.all.PERC.df[,5:19], 2, function(x) sum(x)))
chn.eng.df <- cbind(chn.eng.df, data.frame(apply(eng.all.PERC.df[,5:19], 2, function(x) sum(x))))
colnames(chn.eng.df) <- c(“CHINESE”, “ENGLISH”)
chn.eng.df$novel <- row.names(chn.eng.df)
ggplot(chn.eng.df, aes(x = novel))+
geom_point(aes(y=CHINESE, color = “CHINESE”), shape = 8, size =3) +
geom_point(aes(y=ENGLISH, color = “ENGLISH”), shape = 1, size =3) +
scale_x_discrete(limits=rev(c(“wagahaiwa_nekodearu”,”bocchan”,”kusamakura”,”nihyakutoka”,”nowaki”,”gubijinso”,”kofu”,”sanshiro”,”sorekara”,”mon”,”higansugimade”,”kojin”,”kokoro”,”michikusa”,”meian”))) +
labs(color=”Keywords”)+
ylab(“Freq”) +
coord_flip()
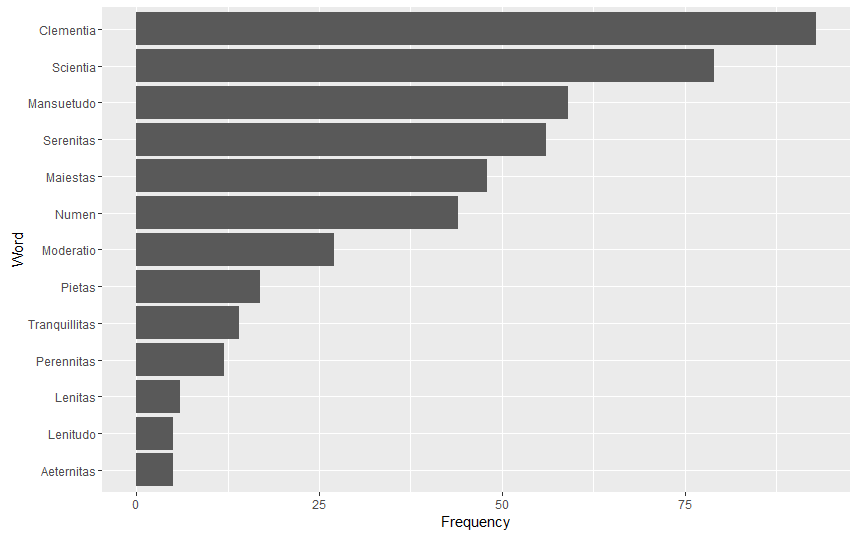
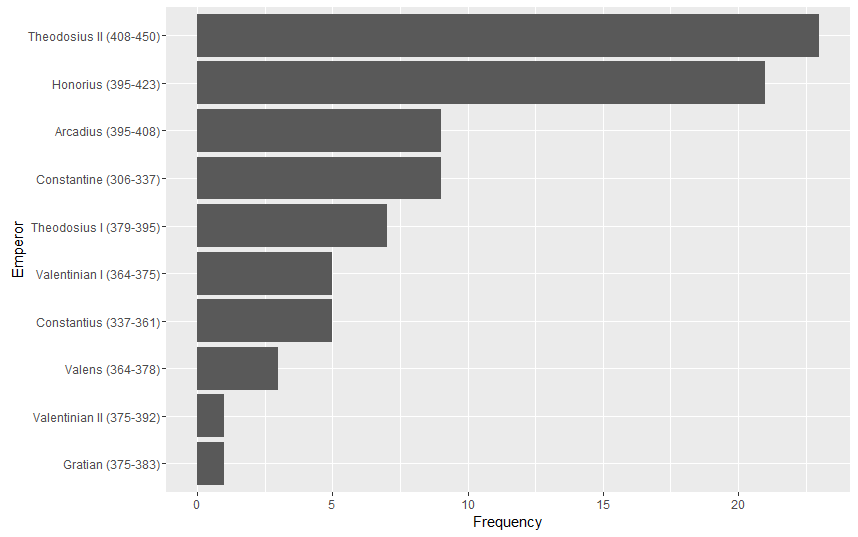
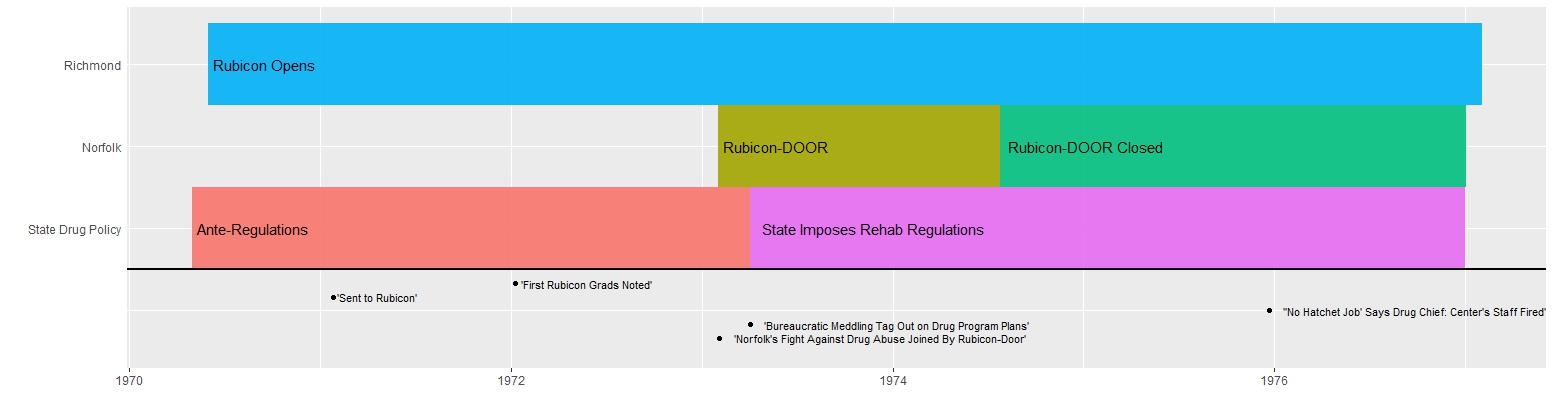

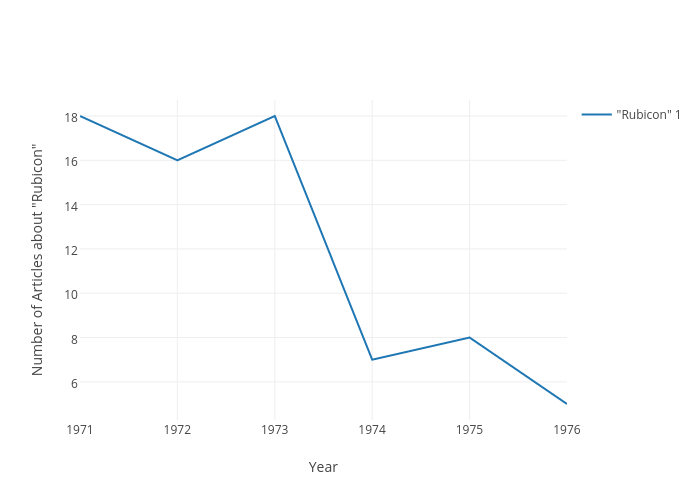
 Using R I selected a few words that indicate Rubicon’s ties to the justice system. Over 66% of Rubicon’s clients were filtered through the justice system. As Indicated below words that exemplify this connection peaked in 1973, right when arrest numbers dropped across the state. Equally notable however is the sharp drop in 1974, which coincided with an increase in arrest numbers from 1973 to 1974. Rubicon either reached capacity or state drug control directives changed. As can be seen words like “probation” were not used continually over time and “convicted” and “sentence” drop out of favor too. This is probably due to a lack of space available at Rubicon after 1973.
Using R I selected a few words that indicate Rubicon’s ties to the justice system. Over 66% of Rubicon’s clients were filtered through the justice system. As Indicated below words that exemplify this connection peaked in 1973, right when arrest numbers dropped across the state. Equally notable however is the sharp drop in 1974, which coincided with an increase in arrest numbers from 1973 to 1974. Rubicon either reached capacity or state drug control directives changed. As can be seen words like “probation” were not used continually over time and “convicted” and “sentence” drop out of favor too. This is probably due to a lack of space available at Rubicon after 1973.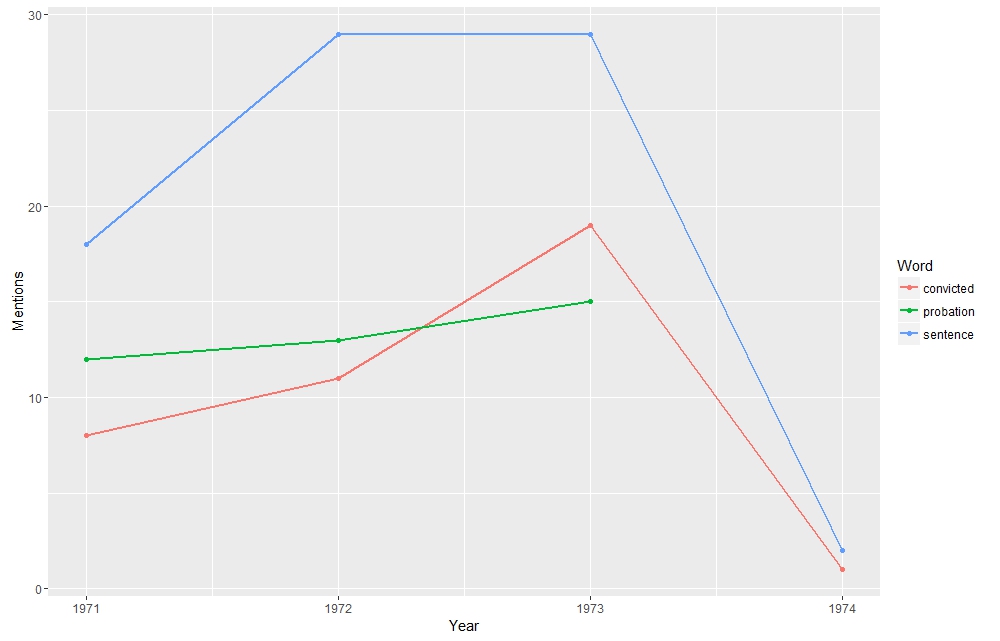 Sentiment Analysis of articles about Rubicon in three Virginia newspapers
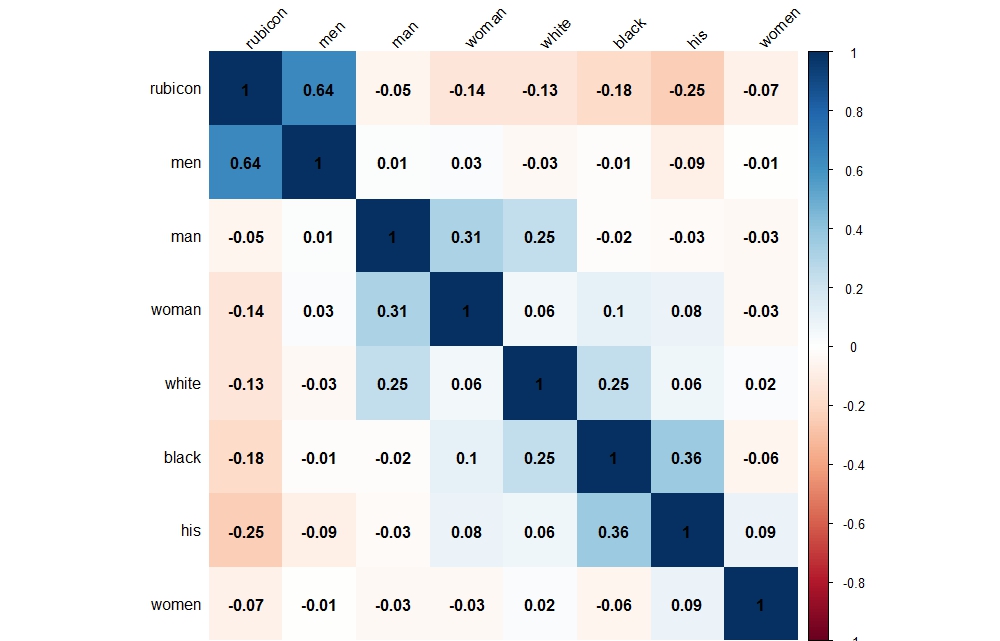
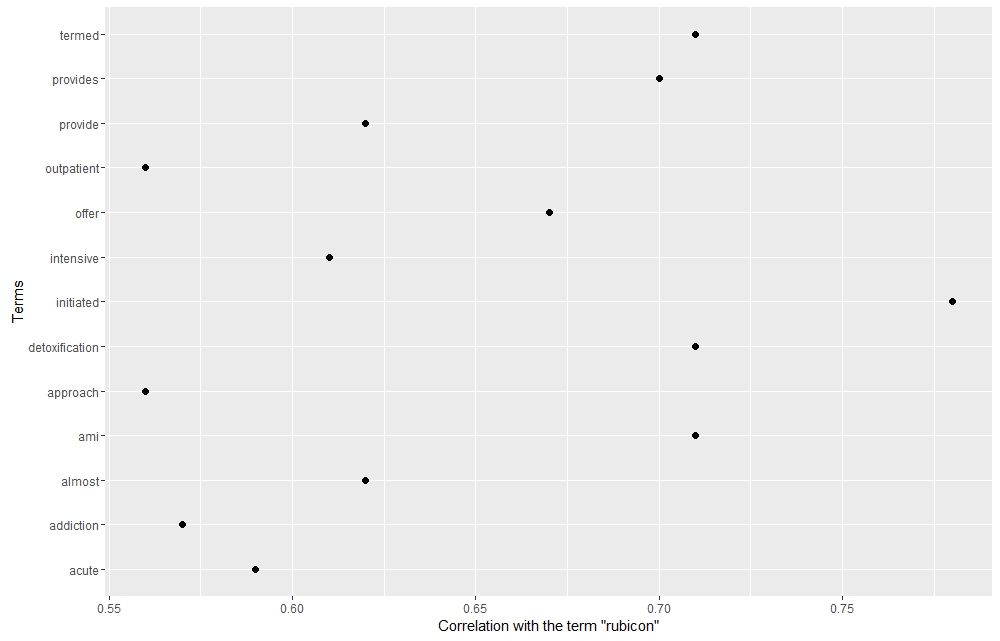
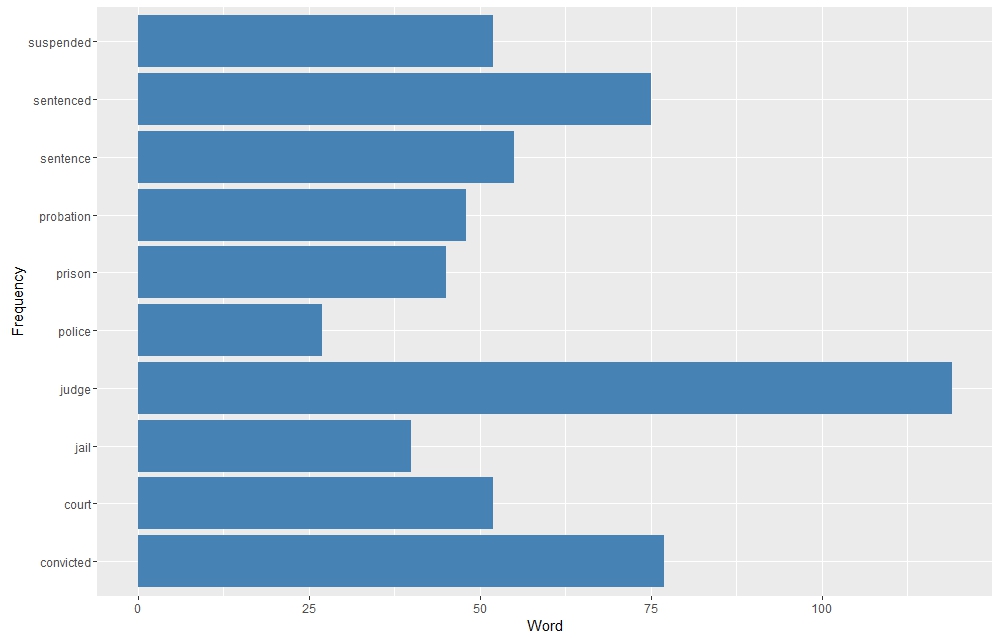
Sentiment Analysis of articles about Rubicon in three Virginia newspapers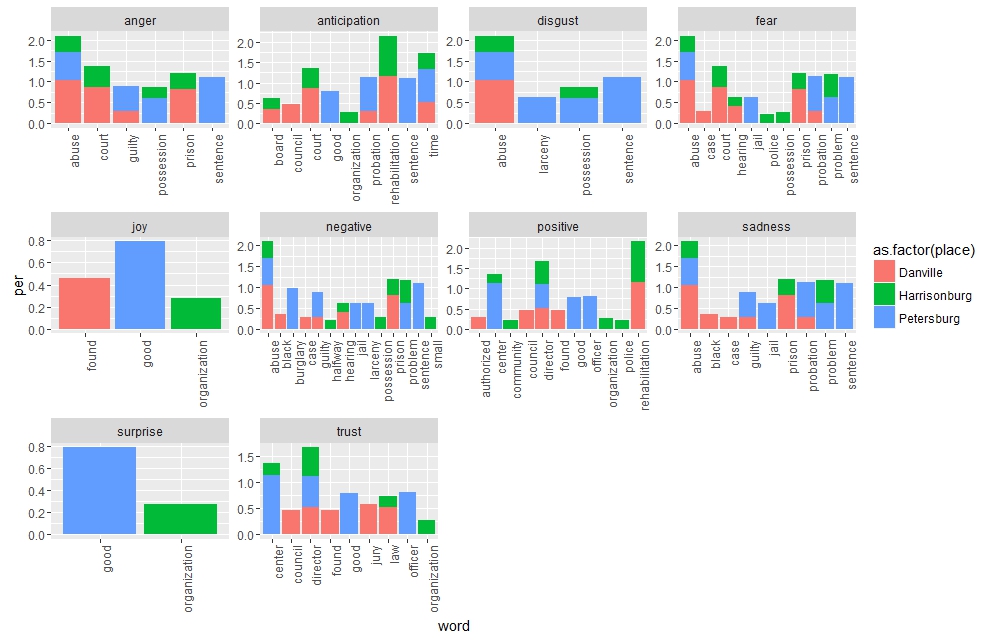 Word cluster of mentions of “police” within the Rubicon corpus. The city of Petersburg is heavily represented.
Word cluster of mentions of “police” within the Rubicon corpus. The city of Petersburg is heavily represented.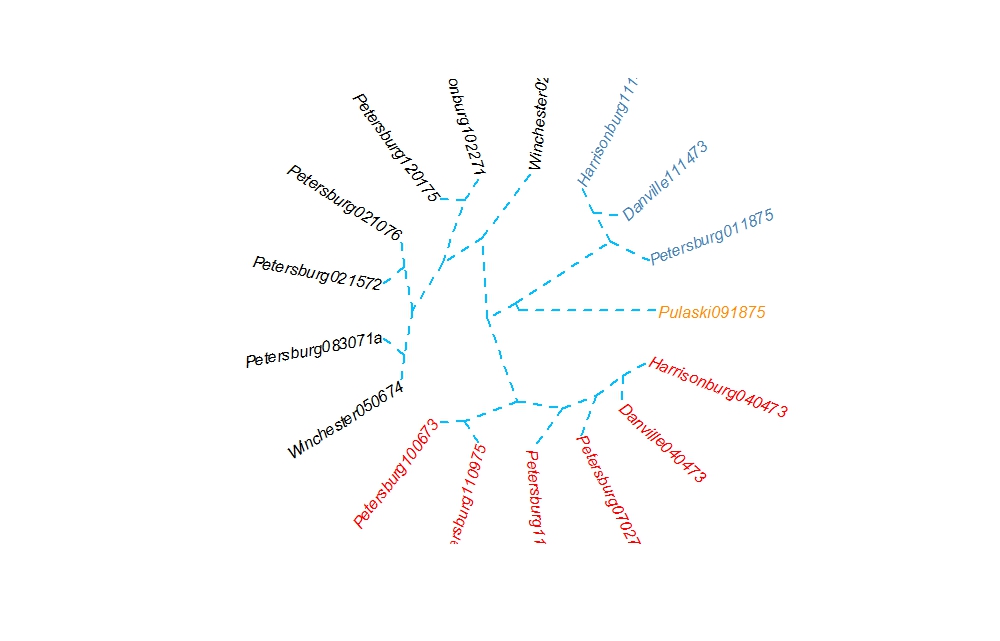
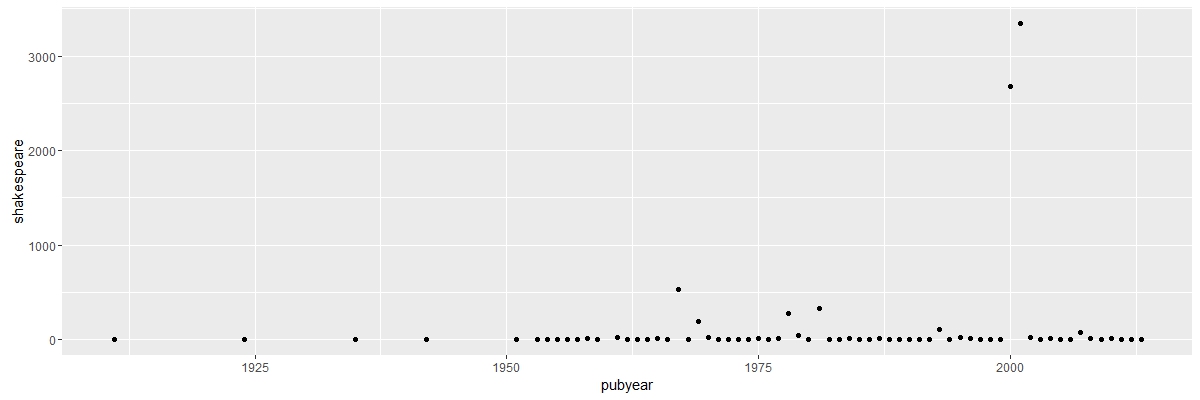 These outliers, however, are not going to seriously affect the study, since I am only interested in counting word frequency and I have a large data set. The code I used is from class. I wrote some new code for graphing and picking frequent word from the document.
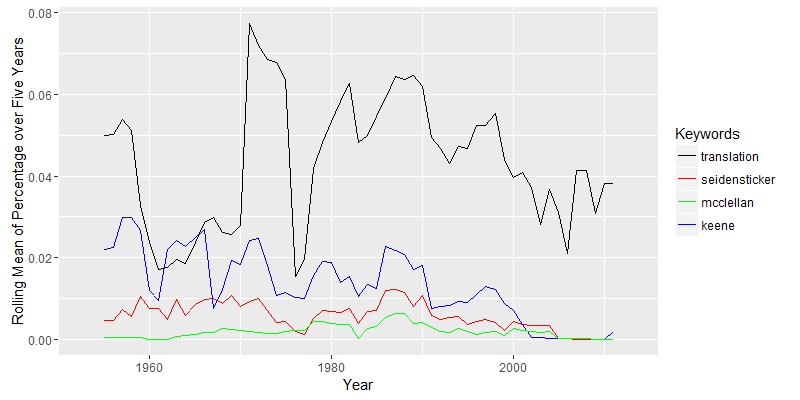
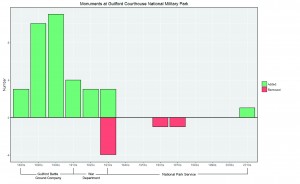
These outliers, however, are not going to seriously affect the study, since I am only interested in counting word frequency and I have a large data set. The code I used is from class. I wrote some new code for graphing and picking frequent word from the document.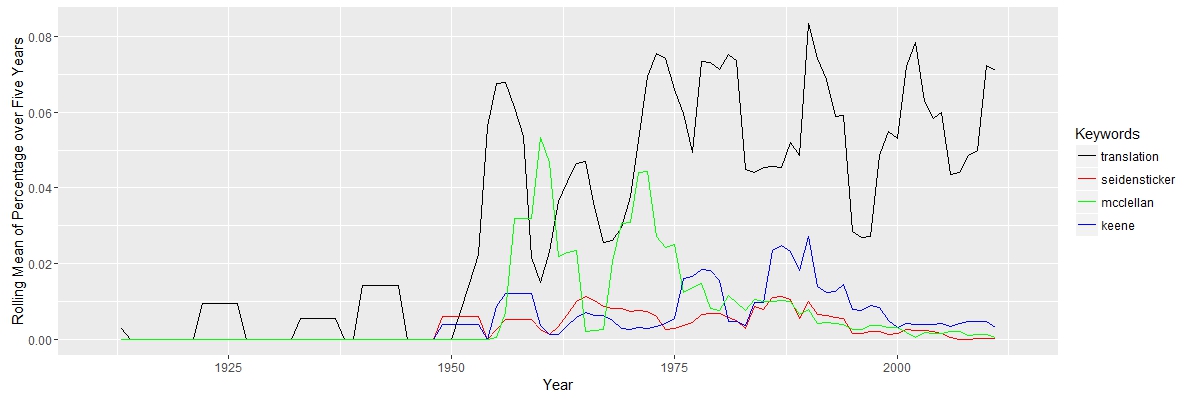 The graph shows that the study of Nastume Soseki’s work in translation rise around 1950. It makes sense, since most of his work was translated after World War II. There are only a few document before 1950 in the result. The key term “translation”, although with some fluctuation, is always important after 1950. Three other keywords “McClellan”, “Keene” and “Seidensticker”, translators’ names, appeared more from 1950 to 2000. The three authors were all born in 1920s, so their works concentrated in the late 20th century.
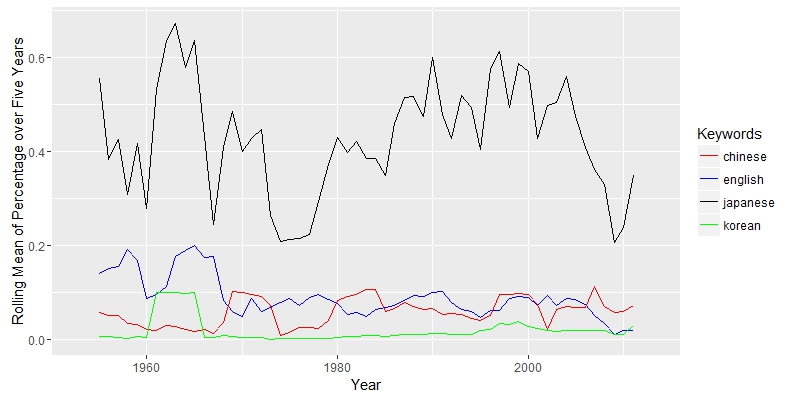
The graph shows that the study of Nastume Soseki’s work in translation rise around 1950. It makes sense, since most of his work was translated after World War II. There are only a few document before 1950 in the result. The key term “translation”, although with some fluctuation, is always important after 1950. Three other keywords “McClellan”, “Keene” and “Seidensticker”, translators’ names, appeared more from 1950 to 2000. The three authors were all born in 1920s, so their works concentrated in the late 20th century.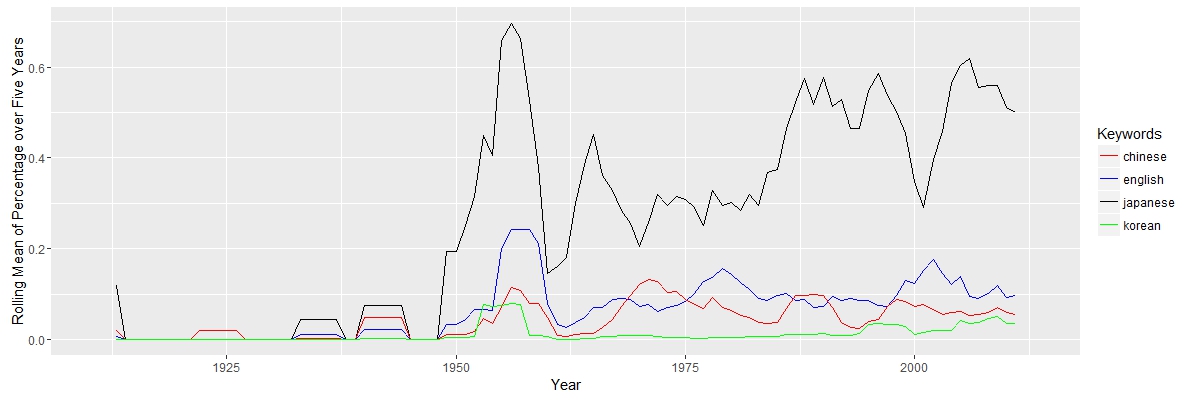 The keyword “Japanese” appeared dominant as expected. Because most of the documents are from Asian studies journals, “Chinese” and “Korean” appears frequently. The line of “English” is close to the line of “Chinese”. If most of works are about translation, the word “English” would appear more. Therefore, there maybe a large portion of the work that does not directly discuss translation; these documents are probably about general literature or cultural study.
The keyword “Japanese” appeared dominant as expected. Because most of the documents are from Asian studies journals, “Chinese” and “Korean” appears frequently. The line of “English” is close to the line of “Chinese”. If most of works are about translation, the word “English” would appear more. Therefore, there maybe a large portion of the work that does not directly discuss translation; these documents are probably about general literature or cultural study.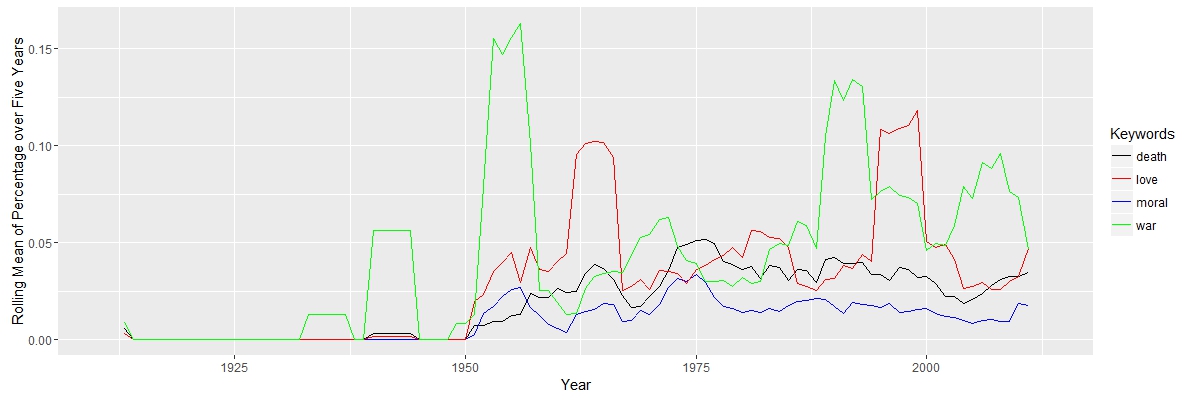
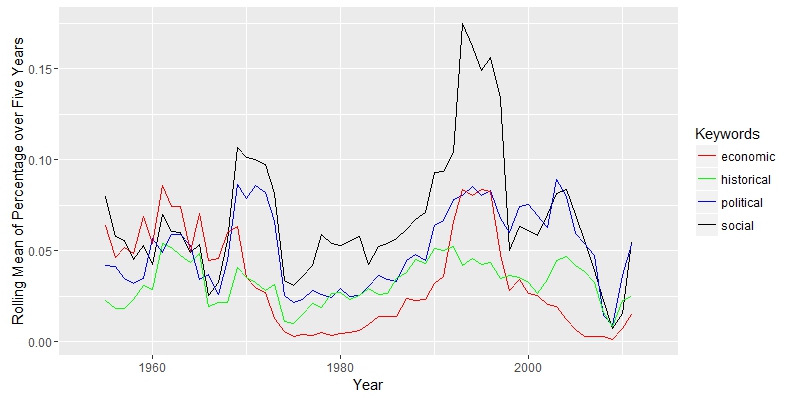
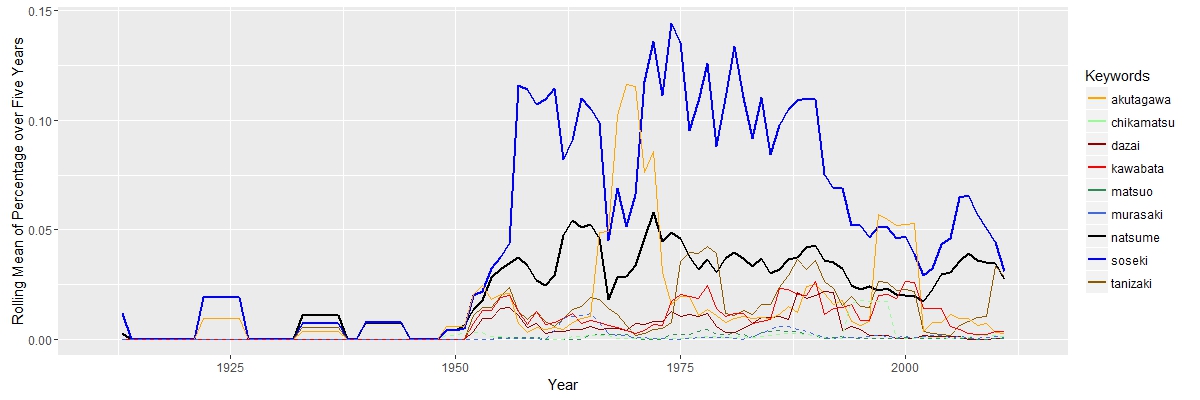
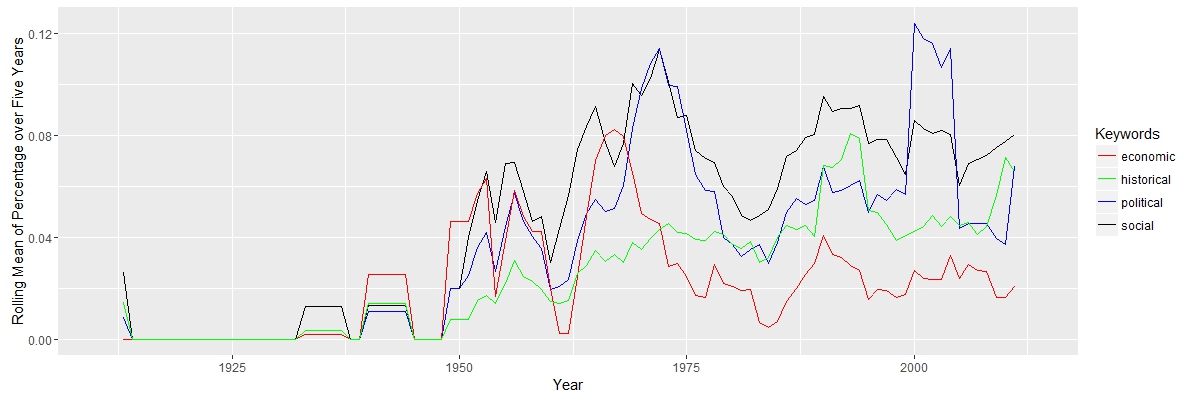 Here, I am interested in how scholars interpreted Natsume’s works and their political, social, economic and historical connections. “Political” and “social” are closely related, since they move together. “Economic” has a falling importance, while “historical” appeared to be more import along the timeline.
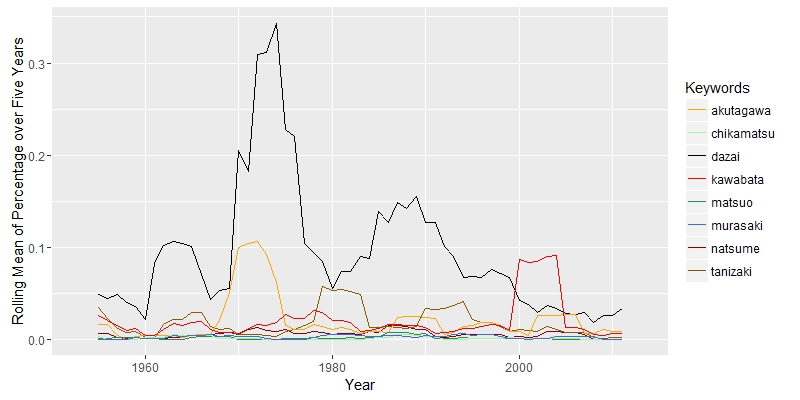
Here, I am interested in how scholars interpreted Natsume’s works and their political, social, economic and historical connections. “Political” and “social” are closely related, since they move together. “Economic” has a falling importance, while “historical” appeared to be more import along the timeline.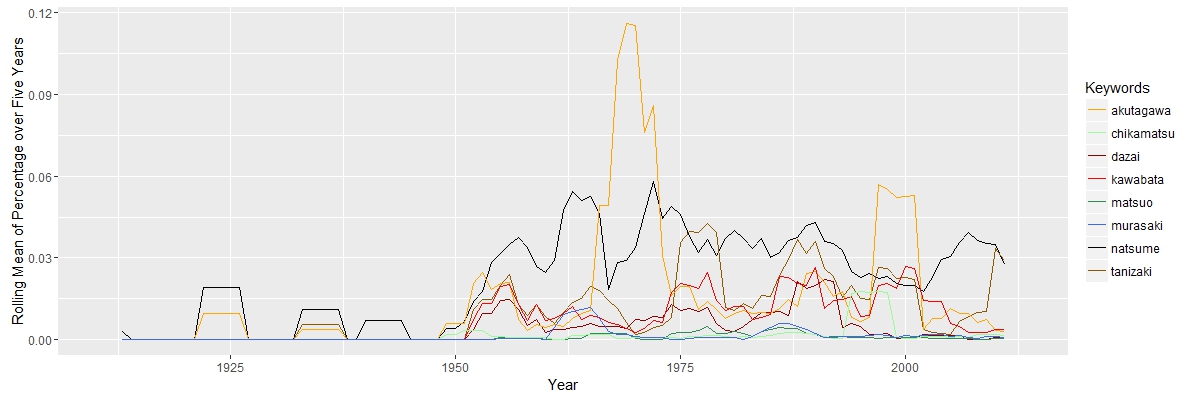 The search for “Natsume Soseki” in JSTOR does not return documents exclusively about Natsume Soseki. Some documents about other Japanese authors may also appear. The graph above shows that “natsume” was constantly above other authors, except years aroud 1965 and 2000, when “akutagawa” has two peaks. The truth is that “akutagawa” appears in total 109 times from 1968 to 1972 and 153 times in 2004. The data set is not perfect, but it will not cause serious bias.
The search for “Natsume Soseki” in JSTOR does not return documents exclusively about Natsume Soseki. Some documents about other Japanese authors may also appear. The graph above shows that “natsume” was constantly above other authors, except years aroud 1965 and 2000, when “akutagawa” has two peaks. The truth is that “akutagawa” appears in total 109 times from 1968 to 1972 and 153 times in 2004. The data set is not perfect, but it will not cause serious bias.