IDEA
My idea is to choose some texts that I have read and compare it to something that I have never read, so I can raise interesting questions based on my previous knowledge. My choices are Pride and Prejudice, A Tale of Two Cities, two novels that I read about 6 years ago, Sense and Sensibility, Mansfield Park, Persuasion, Emma, Great Expectations, and Oliver Twist, which I have never read.
R CODE
I made some improvements to the code from class.
- If I take out punctuation, I will create empty strings (“”). There are words with only punctuation. Thus, I took out the punctuation before eliminating empty strings.
- When I create my data frame, I found that my “Word” column automatically turns to factor. I converted them to character.
#Change the name of the file to import
PRIDE.scan <- scan(“C:/Users/klijia/Desktop/HIST582A/W2/Raw Text/PRIDE.txt”,what=”character”,sep = “\n”)
PRIDE.df <- data.frame(PRIDE.scan, stringsAsFactors = FALSE)
#Select appropriate text
PRIDE.t <- PRIDE.df[c(16:10734),]
PRIDE.string <- paste(PRIDE.t, collapse= ” “)
PRIDE.words <- str_split(string = PRIDE.string, pattern = ” “)
PRIDE.words.good <- unlist(PRIDE.words)
# Take out punctuation before take out empty string “”
# Since there are words consist only punctuations
PRIDE.words.good1 <- str_replace_all(PRIDE.words.good,”[:punct:]”,””)
PRIDE.words.good2 <- PRIDE.words.good1[which(PRIDE.words.good1 != “”)]
PRIDE.words.goodF <- tolower(PRIDE.words.good2)
PRIDE.df <- data.frame(table(PRIDE.words.goodF))
PRIDE.ord.df <- PRIDE.df [order(-PRIDE.df$Freq),]
colnames(PRIDE.ord.df)[1] <- “Word”
# For some reason, the first column of the df is factor. Next line tries to
# convert it into character.
PRIDE.ord.df$Word <- as.character(PRIDE.ord.df$Word)
#Change the name to export file
write.table(PRIDE.ord.df,”C:/Users/klijia/Desktop/HIST582A/W2/Freq/A Tale_Freq.txt”,sep = “\t”)
I used same code for eight novels every time, changing only the import, text selection and output line. Creating a function should make this even more convenient.
Questions
Epistolary Legacy
One thing I remember from my reading of Pride and Prejudice is that Jane Austen likes to use letter in her novels. Early novels are in epistolary style; Austen’s early works are in epistolary form. It is not surprising that Austen preserves some epistolary legacy in her later works. The method that I used to confirm Austen’s preference for letters is to simply calculate the word frequency of “letter” and “letters”. The method is rudimentary and I could not claim that mere use of the words “letter” and “letters” substantiates more usage of letter quote in novels, but the following graphs reveal interesting patterns.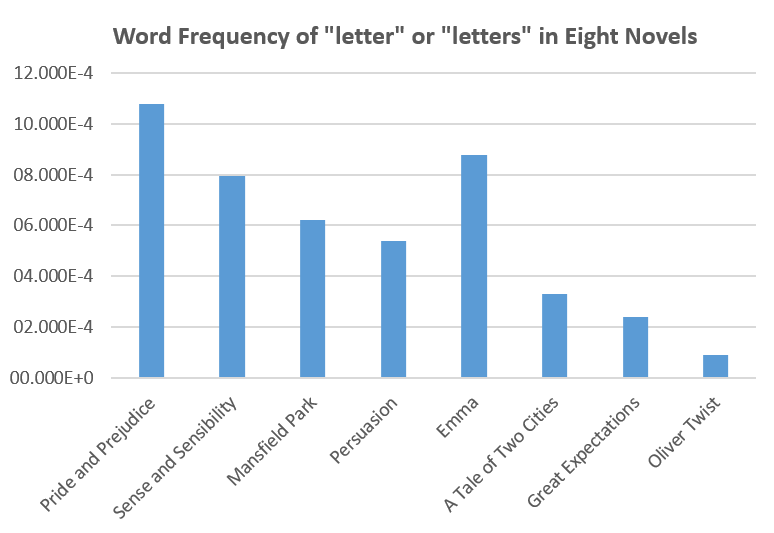
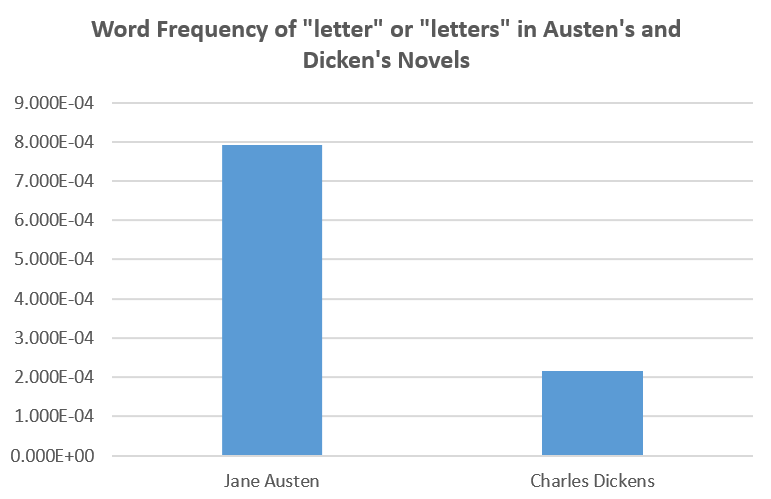
From the graph, I found that Austen uses the words “letter” and “letters” four times as Dickens does. In Pride and Prejudice, every 10.8 in 10,000 words are “letter” or “letters”. Austen’s works retain an epistolary legacy compared to Dickens’ works. This is also correct chronologically, since Dickens comes after Austen.
The Comparison between Pride and Prejudice and Sense and Sensibility
I also did the comparison between Austen’s two novels. Since novels use many proper nouns, I compared the differences in top 300 words. Following are code. I imported the tables created previously before running the codes.
setdiff(Pride_Freq$Word[1:300],Sense_Freq$Word[1:300])
[1] “elizabeth” “darcy” “bennet” “jane” “bingley”
[6] “wickham” “collins” “lydia” “father” “catherine”
[11] “lizzy” “longbourn” “gardiner” “take” “anything”
[16] “aunt” “daughter” “let” “ladies” “netherfield”
[21] “evening” “added” “kitty” “charlotte” “marriage”
[26] “went” “lucas” “answer” “character” “gone”
[31] “passed” “received” “coming” “conversation” “part”
[36] “seeing” “began” “either” “those” “uncle”
[41] “whose” “daughters” “meryton” “means” “party”
[46] “possible” “able” “bingleys” “london” “pemberley”
setdiff(Sense_Freq$Word[1:300],Pride_Freq$Word[1:300])
[1] “elinor” “marianne” “dashwood” “edward” “jennings”
[6] “thing” “willoughby” “lucy” “john” “heart”
[11] “brandon” “ferrars” “barton” “middleton” “mariannes”
[16] “spirits” “person” “against” “feel” “hardly”
[21] “poor” “engagement” “palmer” “acquaintance” “elinors”
[26] “comfort” “cottage” “visit” “within” “brought”
[31] “dashwoods” “short” “continued” “eyes” “general”
[36] “half” “side” “situation” “suppose” “wished”
[41] “end” “norland” “people” “reason” “rest”
[46] “returned” “longer” “park” “took” “under”
Proper nouns are not interesting, so I ignored them. Some of the words that are in Pride and Prejudice, but not in Sense and Sensibility are “father”, “aunt”, “daughter”, “uncle”. Sense and Sensibilities have no frequent words about family member or relatives in the list, so this suggests that Pride and Prejudice concerns more with family relationships. Sense and Sensibilities has more words with negative connotation “poor”, “against”, “hardly”, “cottage” (compare to mansions in Pride and Prejudice). This suggests that Sense and Sensibility tells a sad story, compared to Pride and Prejudice. Of course, through close reading, I can figure out exactly whether Sense and Sensibility deals with family relation or not and whether it is a comedy or tragedy, but the text mining helps me to get a general idea within a few seconds.