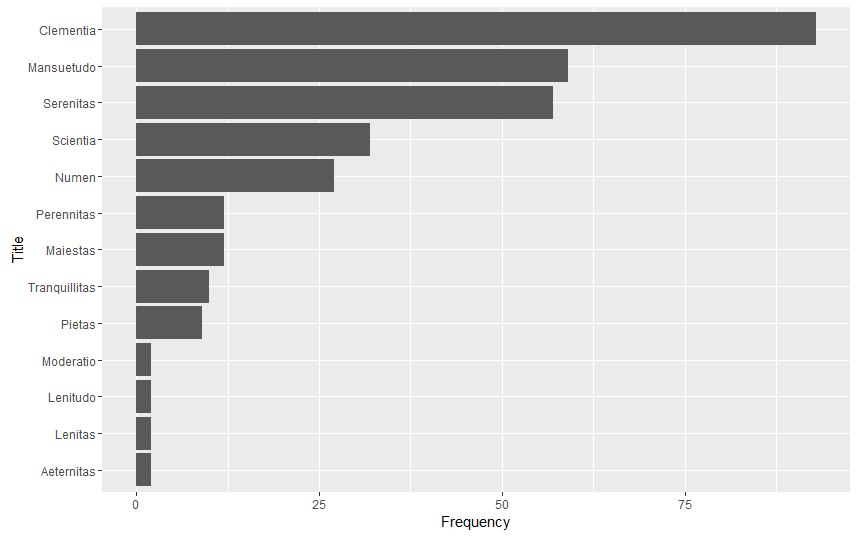
Frequency of Imperial Titles in the Theodosian Code
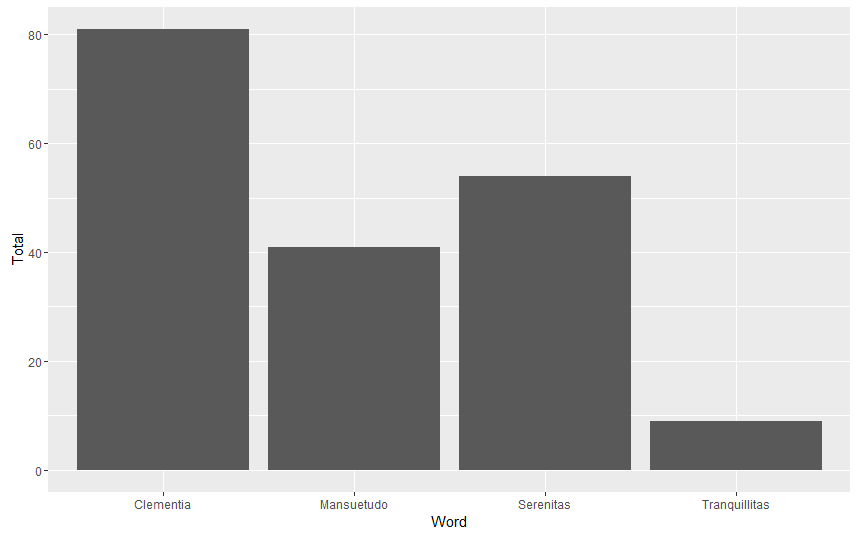
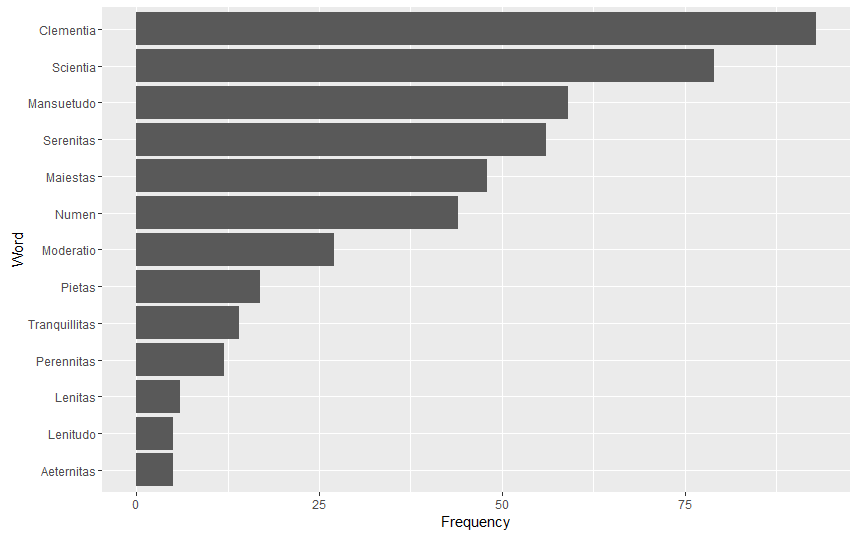
Frequency of Those Words (not just as titles) in the Theodosian Code
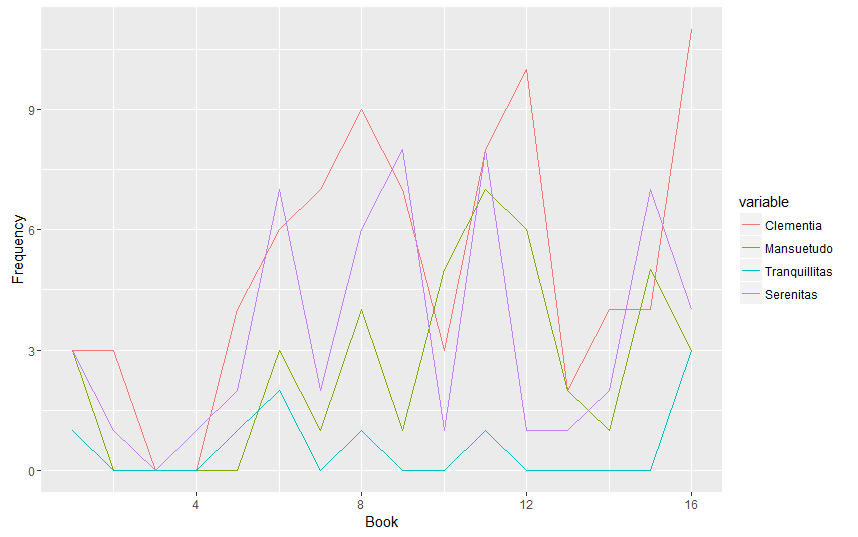
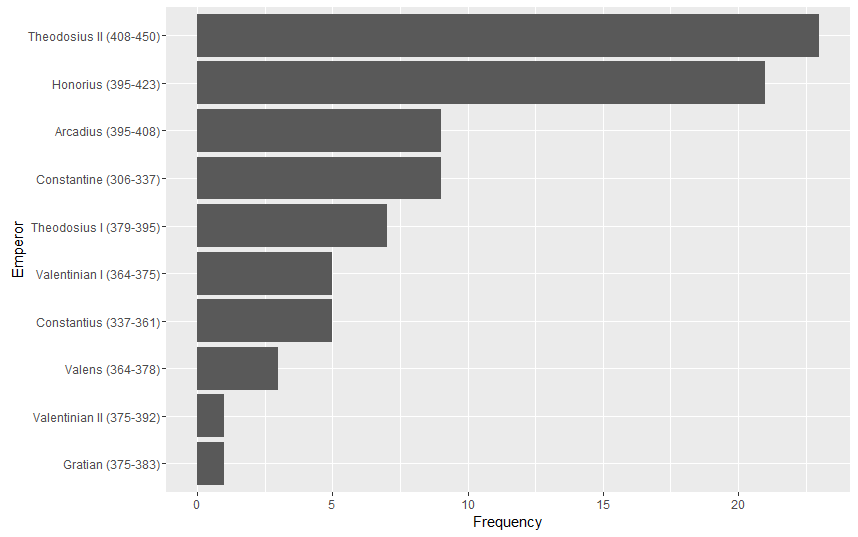
Frequency of Clementia as Imperial Title, by Reign
Code
#THEODOSIAN CODE
CTh.scan <- scan(“~/Education/Emory/Coursework/Digital Humanities Methods/Project/Theodosian Code Raw Text.txt”,
what=”character”, sep=”\n”)
CTh.df <- data.frame(CTh.scan, stringsAsFactors=FALSE)
CTh.df <- str_replace_all(string = CTh.df$CTh.scan, pattern = “[:punct:]”, replacement = “”)
CTh.df <- data.frame(CTh.df, stringsAsFactors = FALSE)
CTh.lines <- tolower(CTh.df[,1])
book.headings <- grep(“book”, CTh.lines)
start.lines <- book.headings + 1
end.lines <- book.headings[2:length(book.headings)] – 1
end.lines <- c(end.lines, length(CTh.lines))
CTh.df <- data.frame(“start” = start.lines, “end”=end.lines, “text”=NA)
i <- 1
for (i in 1:length(CTh.df$end))
{CTh.df$text[i] <- paste(CTh.lines[CTh.df$start[i]:CTh.df$end[i]], collapse = ” “)}
CTh.df$Book <- seq.int(nrow(CTh.df))
#String Extracts of Imperial Titles
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}aeternita.{0,80}|.{0,80}aeternita.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}aeternita.{0,80}|.{0,80}aeternita.{0,80}mea.{0,80}”) #AETERNITAS
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}clementia.{0,80}|.{0,80}clementia.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}clementia.{0,80}|.{0,80}clementia.{0,80}mea.{0,80}”) #CLEMENTIA
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}lenita.{0,80}|.{0,80}lenita.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}lenita.{0,80}|.{0,80}lenita.{0,80}mea.{0,80}”) #LENITAS
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}lenitud.{0,80}|.{0,80}lenitud.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}lenitud.{0,80}|.{0,80}lenitud.{0,80}mea.{0,80}”) #LENITUDO
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}maiesta.{0,80}|.{0,80}maiesta.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}maiesta.{0,80}|.{0,80}maiesta.{0,80}mea.{0,80}”) #MAIESTAS
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}mansuetud.{0,80}|.{0,80}mansuetud.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}mansuetud.{0,80}|.{0,80}mansuetud.{0,80}mea.{0,80}”) #MANSUETUDO
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}moderatio.{0,80}|.{0,80}moderatio.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}moderatio.{0,80}|.{0,80}moderatio.{0,80}mea.{0,80}”) #MODERATIO
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostrum.{0,80}numen.{0,80}|.{0,80}numen.{0,80}nostrum.{0,80}|.{0,80}nostr.{0,80}numin.{0,80}|.{0,80}numin.{0,80}nostr.{0,80}|.{0,80}meum.{0,80}numen.{0,80}|.{0,80}numen.{0,80}meum.{0,80}|.{0,80}me.{0,80}numin.{0,80}|.{0,80}numin.{0,80}me.{0,80}”) #NUMEN
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}perennita.{0,80}|.{0,80}perennita.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}perennita.{0,80}|.{0,80}perennita.{0,80}mea.{0,80}”) #PERENNITAS
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}pieta.{0,80}|.{0,80}pieta.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}pieta.{0,80}|.{0,80}pieta.{0,80}mea.{0,80}”) #PIETAS
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}scientia.{0,80}|.{0,80}scientia.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}scientia.{0,80}|.{0,80}scientia.{0,80}mea.{0,80}”) #SCIENTIA
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}serenita.{0,80}|.{0,80}serenita.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}serenita.{0,80}|.{0,80}serenita.{0,80}mea.{0,80}”) #SERENITAS
str_extract_all(string = CTh.df$text, pattern = “.{0,80}nostra.{0,80}tranquillita.{0,80}|.{0,80}tranquillita.{0,80}nostra.{0,80}|.{0,80}mea.{0,80}tranquillita.{0,80}|.{0,80}tranquillita.{0,80}mea.{0,80}”) #TRANQUILLITAS
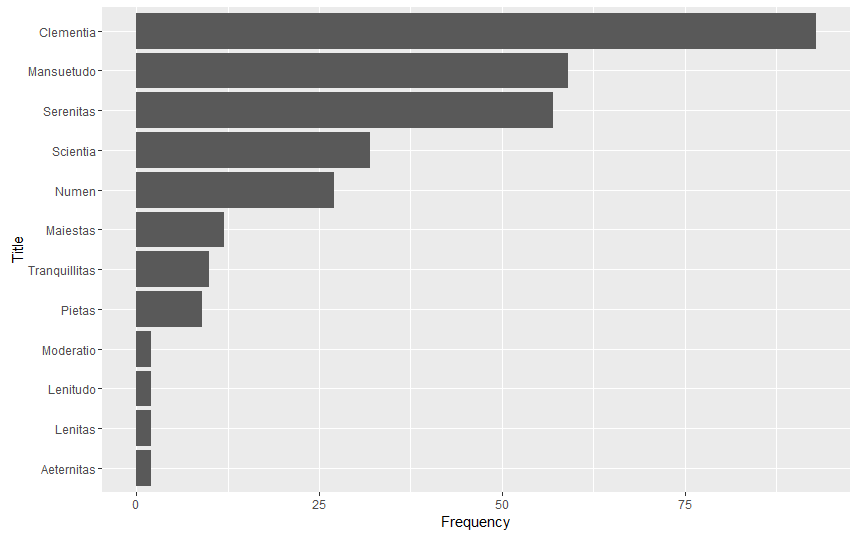
#Imperial Title Sums
aeternitas <- 2
clementia <- 93
lenitas <- 2
lenitudo <- 2
maiestas <- 12
mansuetudo <- 59
moderatio <- 2
numen <- 27
perennitas <- 12
pietas <- 9
scientia <- 32
serenitas <- 57
tranquillitas <- 10
#Imperial Title Sum Graph
Frequency <- c(aeternitas, clementia, lenitas, lenitudo, maiestas, mansuetudo, moderatio, numen, perennitas, pietas, scientia, serenitas, tranquillitas)
Title <- c(“Aeternitas”, “Clementia”, “Lenitas”, “Lenitudo”, “Maiestas”, “Mansuetudo”, “Moderatio”, “Numen”, “Perennitas”, “Pietas”, “Scientia”, “Serenitas”, “Tranquillitas”)
sum.df <- cbind.data.frame(Title, Frequency)
sum.df$Title <- factor(sum.df$Title, levels = sum.df$Title[order(sum.df$Frequency)]) #Reorders dataframe based on Frequency
ggplot(data=sum.df, aes(x=Title, Frequency), y=Frequency) + geom_bar(stat = “identity”) + coord_flip() #Word Total Graph
#Non-Title Frequencies
aeternitas <- sum(str_count(CTh.df$text, “aeternita”), na.rm = TRUE)
clementia <- sum(str_count(CTh.df$text, “clementia”), na.rm = TRUE)
lenitas <- sum(str_count(CTh.df$text, “lenita”), na.rm = TRUE)
lenitudo <- sum(str_count(CTh.df$text, “lenitud”), na.rm = TRUE)
maiestas <- sum(str_count(CTh.df$text, “maiesta”), na.rm = TRUE)
mansuetudo <- sum(str_count(CTh.df$text, “mansuetud”), na.rm = TRUE)
moderatio <- sum(str_count(CTh.df$text, “moderatio”), na.rm = TRUE)
numen <- sum(str_count(CTh.df$text, “numen|numin”), na.rm = TRUE)
perennitas <- sum(str_count(CTh.df$text, “perennita”), na.rm = TRUE)
pietas <- sum(str_count(CTh.df$text, “pieta”), na.rm = TRUE)
scientia <- sum(str_count(CTh.df$text, “scientia”), na.rm = TRUE)
serenitas <- sum(str_count(CTh.df$text, “serenita”), na.rm = TRUE)
tranquillitas <- sum(str_count(CTh.df$text, “tranquillita”), na.rm = TRUE)
Frequency <- c(aeternitas, clementia, lenitas, lenitudo, maiestas, mansuetudo, moderatio, numen, perennitas, pietas, scientia, serenitas, tranquillitas)
Title <- c(“Aeternitas”, “Clementia”, “Lenitas”, “Lenitudo”, “Maiestas”, “Mansuetudo”, “Moderatio”, “Numen”, “Perennitas”, “Pietas”, “Scientia”, “Serenitas”, “Tranquillitas”)
sum.df <- cbind.data.frame(Title, Frequency)
sum.df$Title <- factor(sum.df$Title, levels = sum.df$Title[order(sum.df$Frequency)]) #Reorders dataframe based on Frequency
ggplot(data=sum.df, aes(x=Title, Frequency), y=Frequency) + geom_bar(stat = “identity”) + coord_flip() #Word Total Graph
#Title Frequency By Reign
constantine <- 9
constantius <- 5
valentinian1 <- 5
valens <- 3
gratian <- 1
valentinian2 <- 1
theodosius1 <- 7
honorius <- 21
arcadius <- 9
theodosius2 <- 23
Frequency <- c(constantine, constantius, valentinian1, valens, gratian, valentinian2, theodosius1, honorius, arcadius, theodosius2)
Title <- c(“Constantine (306-337)”, “Constantius (337-361)”, “Valentinian I (364-375)”, “Valens (364-378)”, “Gratian (375-383)”, “Valentinian II (375-392)”, “Theodosius I (379-395)”, “Honorius (395-423)”, “Arcadius (395-408)”, “Theodosius II (408-450)”)
sum.df <- cbind.data.frame(Title, Frequency)
sum.df$Title <- factor(sum.df$Title, levels = sum.df$Title[order(sum.df$Frequency)]) #Reorders dataframe based on Frequency
ggplot(data=sum.df, aes(x=Title, Frequency), y=Frequency) + geom_bar(stat = “identity”) + labs(x = “Emperor”) + coord_flip() #Word Total Graph